Lowering
Lowering lowers the Top layer OP to the Tpu layer OP, it supports types of F32/F16/BF16/INT8 symmetric/INT8 asymmetric.
When converting to INT8, it involves the quantization algorithm. For different chips, the quantization algorithm is different. For example, some support per-channel and some do not. Some support 32-bit Multiplier and some only support 8-bit, etc.
Therefore, lowering converts op from the chip-independent layer (TOP), to the chip-related layer (TPU).
Basic Process
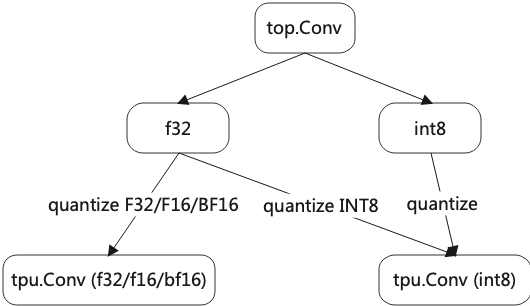
The process of lowering is shown in the figure (Lowering process).
Top op can be divided into f32 and int8. The former is the case of most networks and the latter is the case of quantized networks such as tflite.
f32 op can be directly converted to f32/f16/bf16 tpu layer operator. If it is to be converted to int8, the type should be calibrated_type.
int8 op can only be directly converted to tpu layer int8 op.
Mixed precision
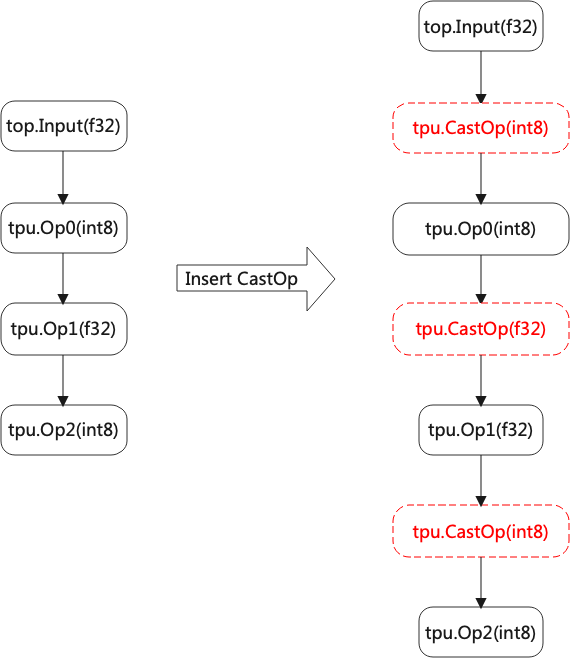
When the type is not the same between OPs, CastOp is inserted as shown in the figure (Mixed precision).
It is assumed that the type of output is the same as the input. Otherwise, special treatment is needed. For example, no matter what the type of embedding output is, the input is of type uint.