Models
Vision · speech · LLMs — running on TPUs today.
A non-exhaustive snapshot of the families that ship through TPU-MLIR's regression and demo flow.
Vision
★YOLOv5
★YOLOv8
ResNet
MobileNet
SAM
Stable Diffusion
Speech
★Whisper
Paraformer
FunASR
Large Language Models
★Qwen3.5
★Qwen3-VL
★MiniCPM-V-4
…and more

YOLOv5s — output comparison across F32 / F16 / INT8 bmodels.
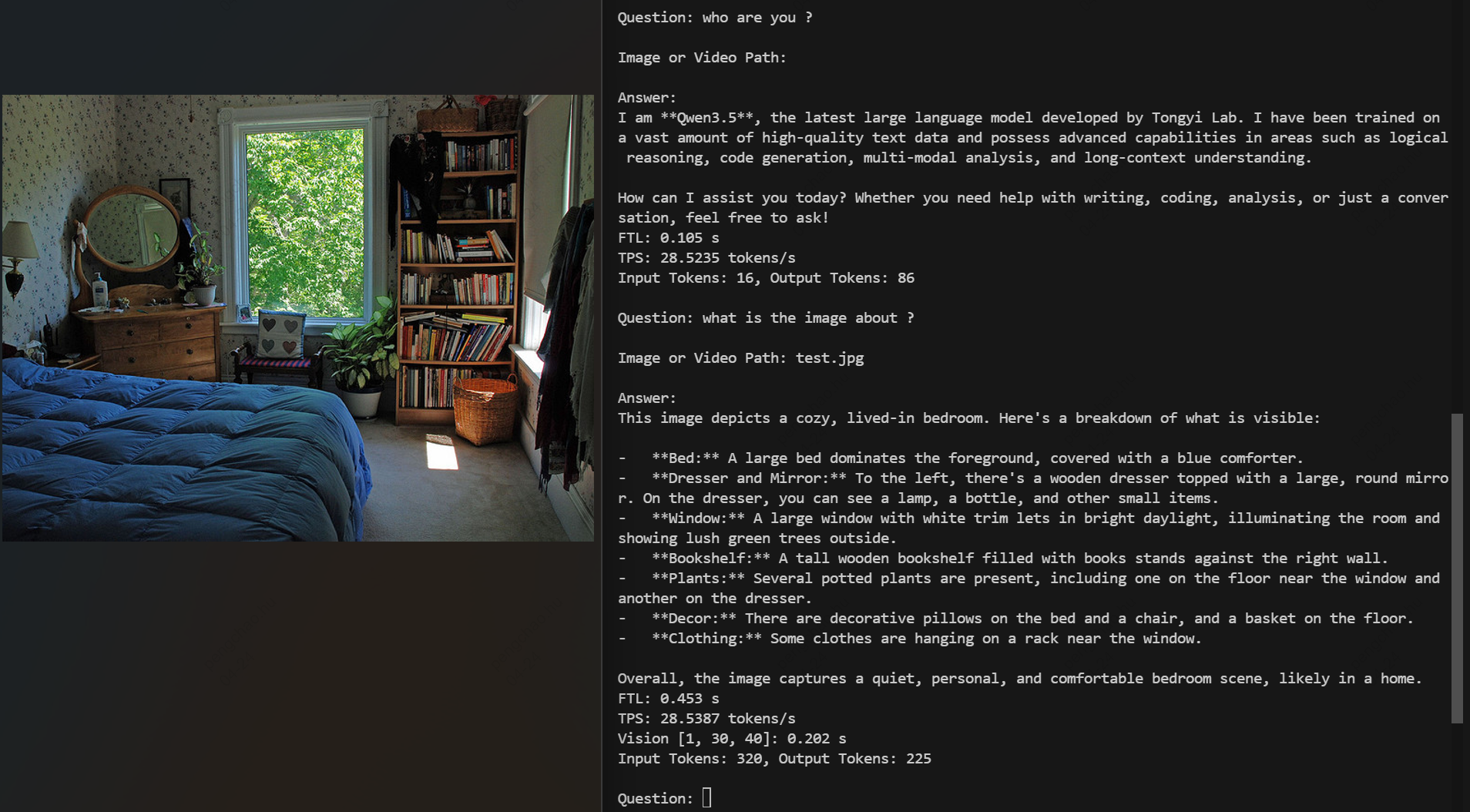
Qwen3.5-2B (INT4 / AutoRound) compiled with
llm_convert.py and chatting on a Sophgo BM1684X.