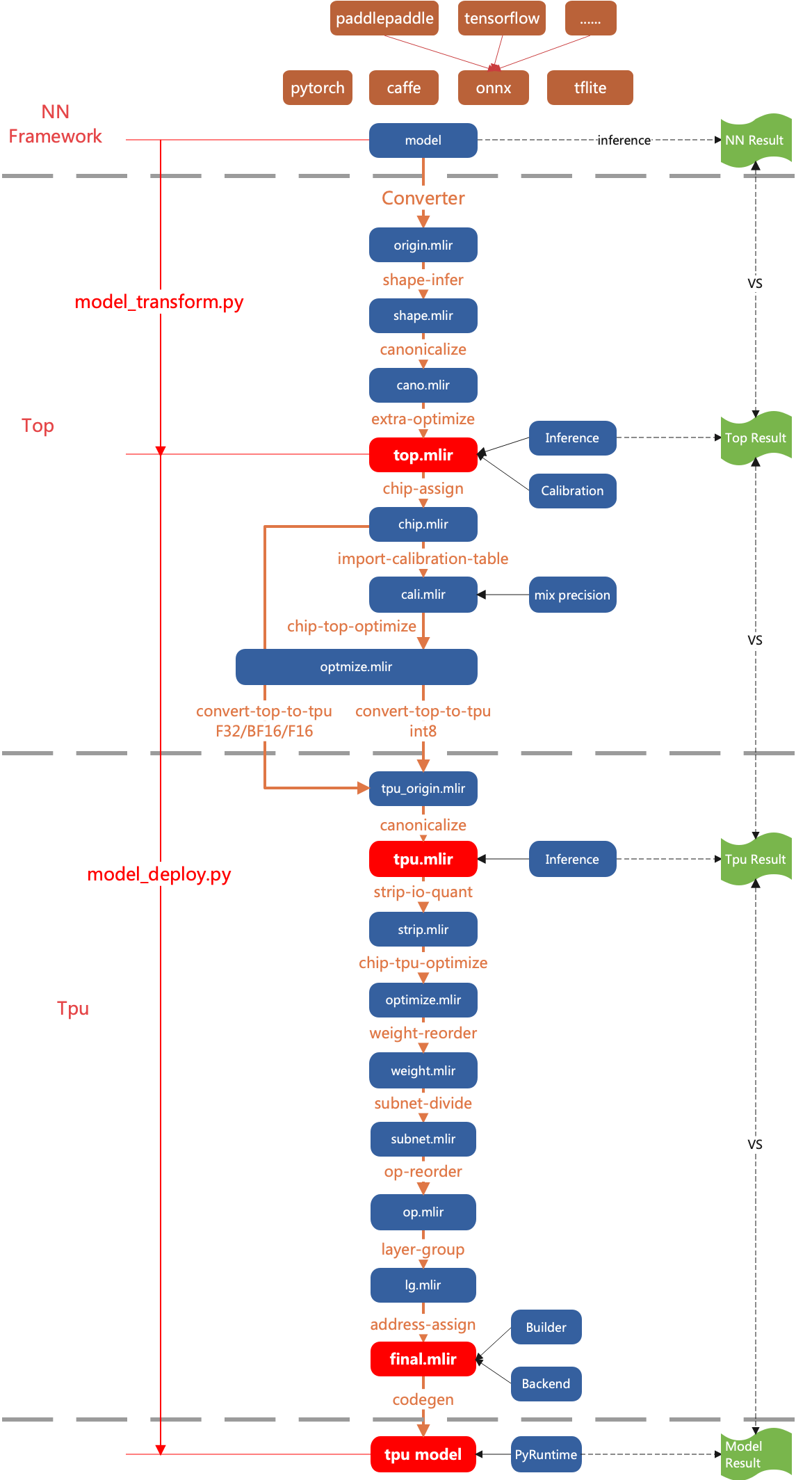
整体设计
分层
TPU-MLIR将网络模型的编译过程分两层处理:
- Top Dialect
-
与芯片无关层, 包括图优化、量化、推理等等
- Tpu Dialect
-
与芯片相关层, 包括权重重排、算子切分、地址分配、推理等等
整体的流程如(TPU-MLIR整体流程)图中所示, 通过Pass将模型逐渐转换成最终的指令, 这里具体说明Top层和Tpu层每个Pass做的什么功能。 后面章节会对每个Pass的关键点做详细说明。