LayerGroup
基本概念
TPU芯片分为片外内存(或称Global Memory, 简称GMEM)和片内内存(或称Local Memory, 简称LMEM)。
通常片外内存非常大(比如4GB), 片内内存非常小(比如16MB)。神经网络模型的数据量和计算量
都非常大, 通常每层的OP都需要切分后放到Local Memory进行运算, 结果再保存到Global Memory。
LayerGroup就是让尽可能多的OP经过切分后能够在Local Memroy执行, 而避免过多的Local和Grobal Memory的拷贝。
- 要解决的问题:
-
如何使Layer数据保持在有限的Local Memory进行运算, 而不是反复进行Local与Global Memory之间的拷贝
- 基本思路:
-
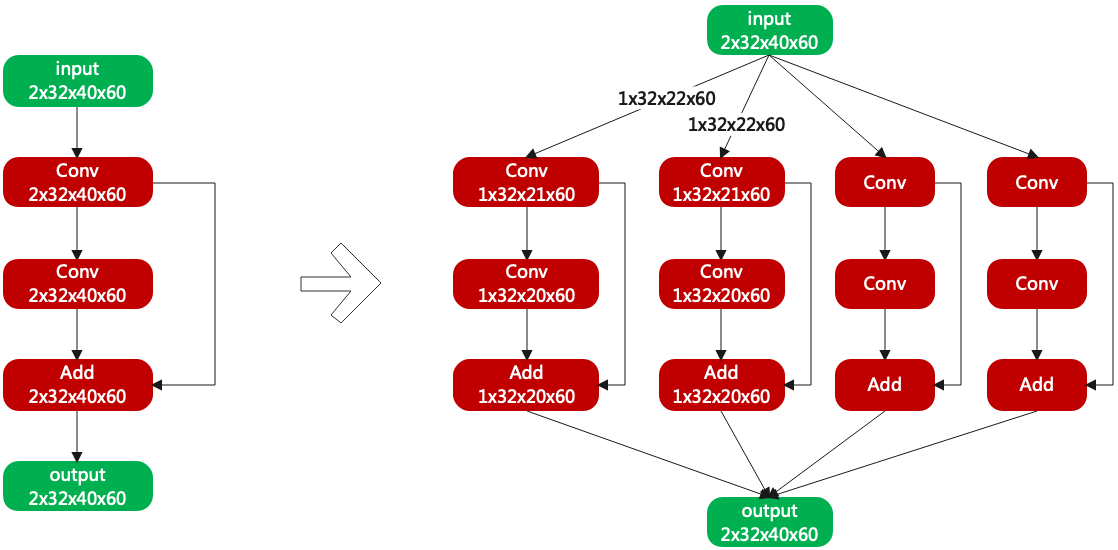
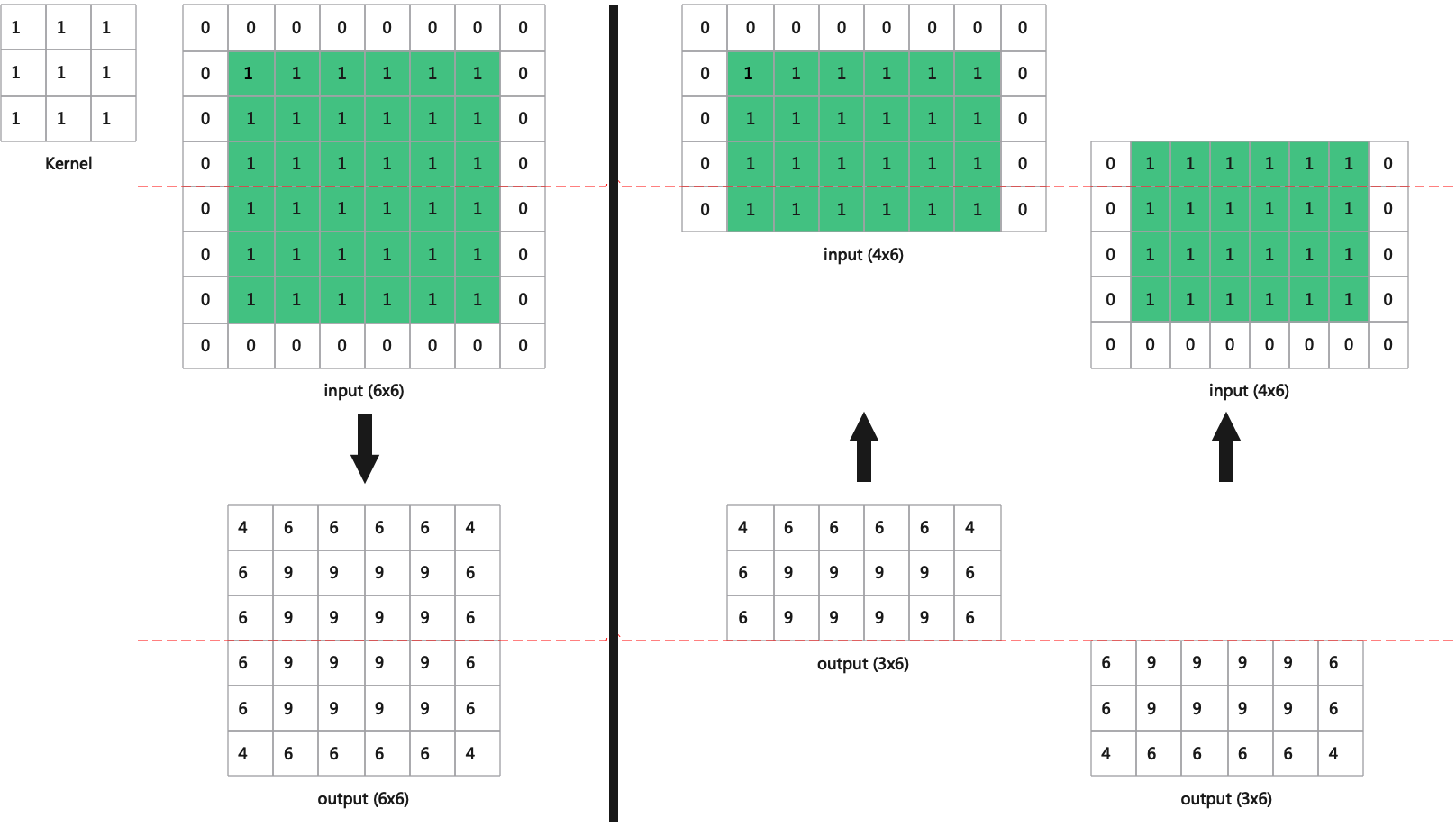
通过切Activation的N和H, 使每层Layer的运算始终在Local Memory中, 如图(网络切分举例)
划分Mem周期
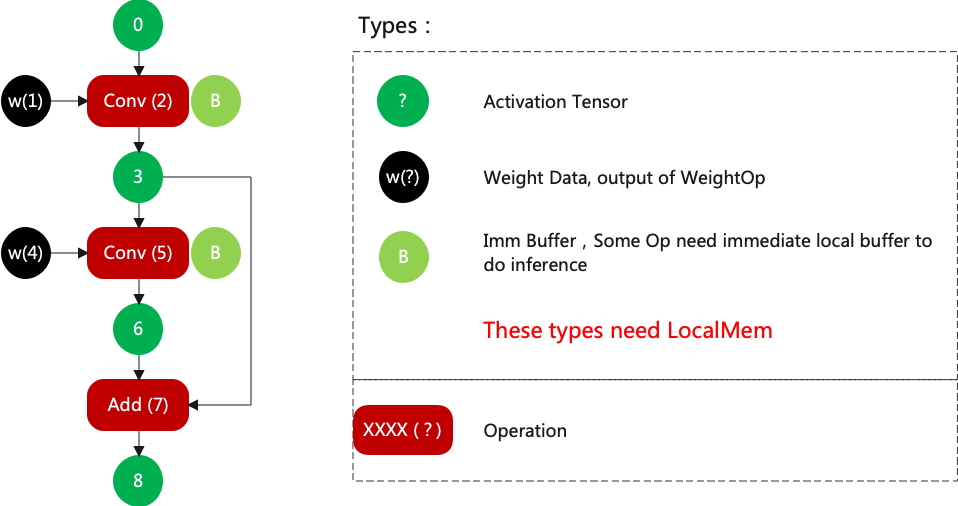
如何划分group? 首先把每一层Layer需要的lmem罗列出来, 大体可以归为三类:
Activation Tensor, 用于保存输入输出结果, 没有使用者后直接释放
Weight, 用于保存权重, 不切的情况下用完就释放; 否则一直驻留在lmem
Buffer, 用于Layer运算保存中间结果, 用完就释放
然后依次广度优先的方式配置id, 举例如图(LMEM的ID分配)
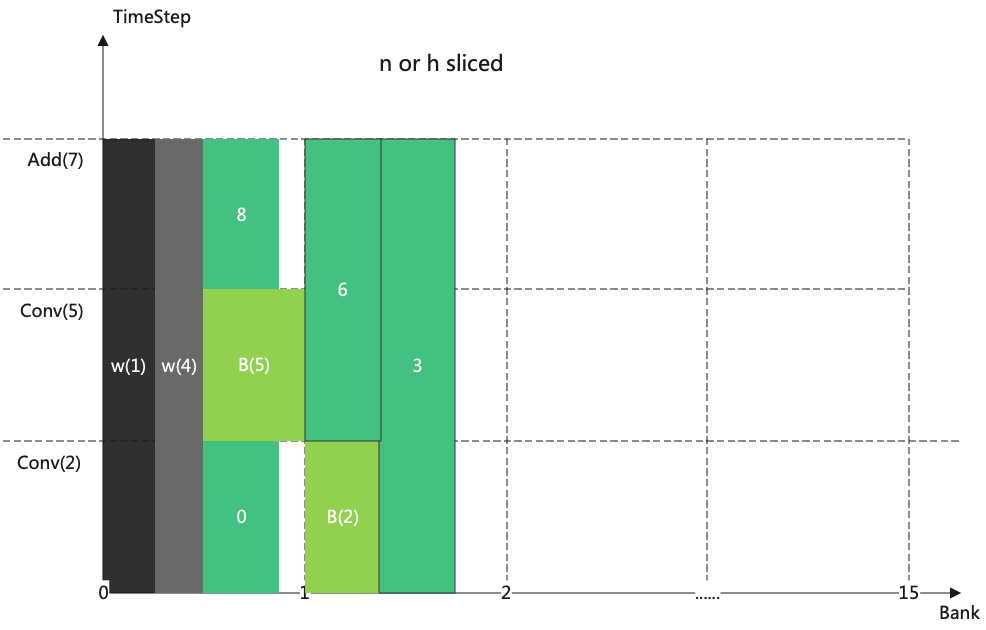
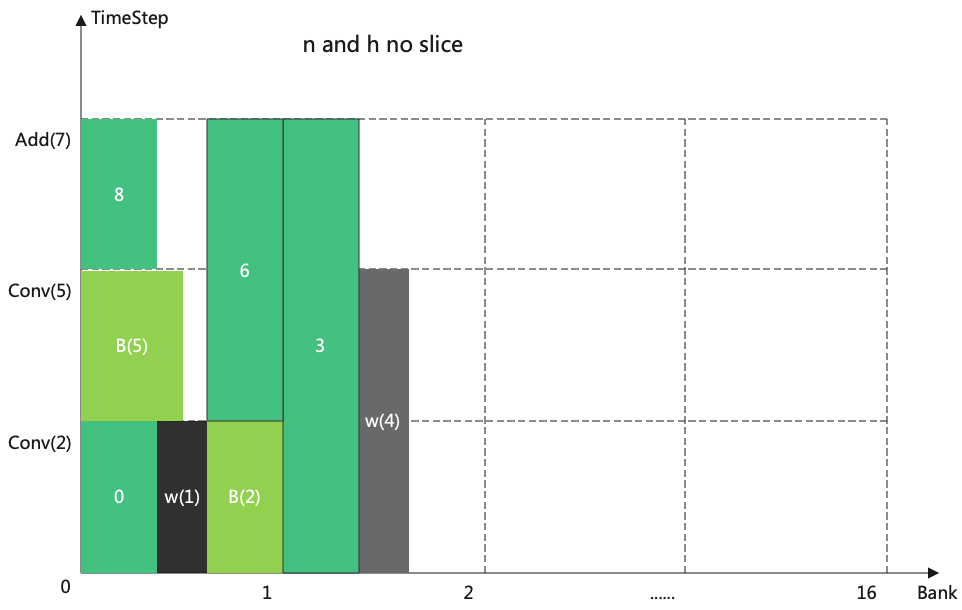
然后再配置周期, 配置方法如图(TimeStep分配)
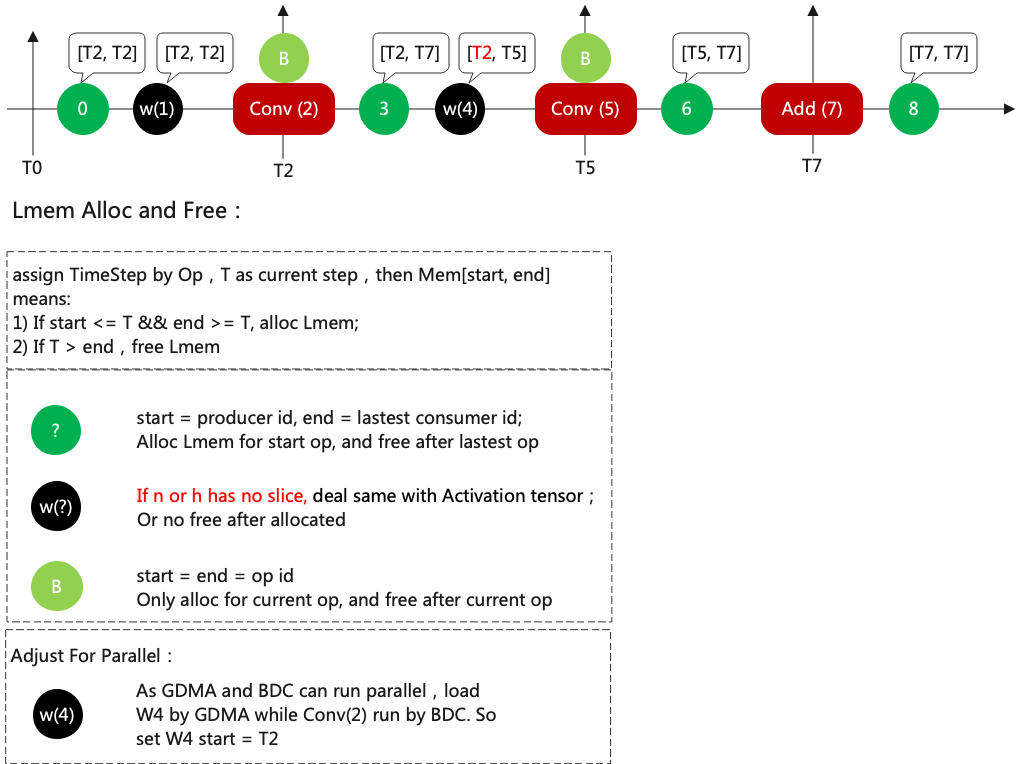
关于配置周期的细节如下:
[T2,T7], 表示在T2开始的时候就要申请lmem, 在T7结束的时候释放lmem
w4的原始周期应该是[T5,T5], 但是被修正成[T2,T5], 因为在T2做卷积运算时w4可以被同时加载
当N或者H被切分时, Weight不需要重新被加载, 它的结束点会被修正为正无穷