QAT量化感知训练
基本原理
相比训练后量化因为其不是全局最优而导致的精度损失,QAT量化感知训练能做到基于loss优化的全局最优而尽可能的降低量化精度损失,其基本原理是:在fp32模型训练中就提前引入推理时量化导致的权重和激活的误差,用任务loss在训练集上来优化可学习的权重及量化的scale和zp值,当任务loss即使面临这个量化误差的影响,也能经学习达到比较低的loss值时,在后面真正推理部署量化时,因为量化引入的误差早已在训练时被很好的适应了,只要能保证推理和训练时的计算完全对齐,理论上就保证了推理时量化不会有精度损失。
tpu-mlir QAT实现方案及特点
主体流程
用户训练时,调用模型QAT量化API对训练模型进行修改:推理时op融合后需要量化的op的输入(包括权重和bias)前插入伪量化节点(可配置该节点的量化参数,比如per-chan/layer、是否对称、量化比特数等),然后用户使用修改后模型进行正常的训练流程,完成少数几个轮次的训练后,调用转换部署API接口将训练过的模型转为fp32权重的onnx模型,提取伪量化节点中参数导出到量化参数文本文件中,最后将调优后的onnx模型和该量化参数文件输入到tpu-mlir工具链中,按前面讲的训练后量化方式转换部署即可。
方案特点
特点1:基于pytorch;QAT是训练pipeline的一个附加finetune环节,只有与训练环境深度集成才能方便用户各种使用场景,考虑pytorch具有最广泛的使用率,故目前方案仅基于pytorch,若qat后续要支持其他框架,方案会大不相同,其trace、module替换等机制深度依赖原生训练平台的支持.
特点2:客户基本无感;区别于早期需人工深度介入模型转换的方案,本方案基于pytorch fx,能实现自动的完成模型trace、伪量化节点插入、自定义模块替换等操作,大多数情况下,客户使用默认配置即可一键式完成模型转换.
特点3:基于商汤开源的mqbench qat训练框架,已有一定的社区基础,方便工业界和学术界在我司tpu上进行推理性能和精度评估;
安装方法
从源码安装
1、执行命令获取github上最新代码:git clone https://github.com/sophgo/MQBench
2、进入MQBench目录后执行:
pip install -r requirements.txt #注:当前要求torch版本为1.10.0
python setup.py install3、执行python -c ‘import mqbench’若没有返回任何错误,则说明安装正确,若安装有错,执行pip uninstall mqbench卸载后再尝试;
基本步骤
步骤一:接口导入及模型prepare
在训练文件中添加如下python模块import接口:
from mqbench.prepare_by_platform import prepare_by_platform, BackendType #初始化接口
from mqbench.utils.state import enable_calibration, enable_quantization #校准和量化开关
from mqbench.convert_deploy import convert_deploy #转换部署接口
#使用torchvision model zoo里的预训练resnet18模型
model = torchvision.models.__dict__["resnet18"](pretrained=True)
Backend = BackendType.sophgo_tpu
#1.trace模型,然后基于sophgo_tpu硬件的要求添加特定方式的量化节点
model_quantized = prepare_by_platform(model, Backend)当上面接口选择sophgo_tpu后端时,该接口的第3个参数prepare_custom_config_dict默认不用配置,此时默认的量化配置如下图所示:

上图sophgo_tpu后端的dict中各项从上到下依次意义为:
1、权重量化方案为: per-chan对称8bit量化,scale系数不是power-of-2,而是任意的
2、激活量化方案为:per-layer非对称8bit量化
3/4、权重和激活伪量化方案均为:LearnableFakeQuantize即LSQ算法
5/6、权重的动态范围统计及scale计算方案为:MinMaxObserver,激活的为带EMA指数移动平均的EMAMinMaxObserver
步骤2:用于量化参数初始化的校准及量化训练
#1.打开校准开关,容许在模型上推理时用pytorch observer对象来收集激活分布并计算初始scale和zp
enable_calibration(model_quantized)
# 校准循环
for i, (images, _) in enumerate(cali_loader):
model_quantized(images) #只需要前向推理即可
#3.打开伪量化开关,在模型上推理时会调用QuantizeBase子对象来进行伪量化操作引入量化误差
enable_quantization(model_quantized)
# 训练循环
for i, (images, target) in enumerate(train_loader):
#前向推理并计算loss
output = model_quantized(images)
loss = criterion(output, target)
#后向反传梯度
loss.backward()
#更新权重和伪量化参数
optimizer.step()使用样例-resnet18
执行example/imagenet_example/main.py对resent18进行qat训练,命令如下:
python3 imagenet_example/main.py
--arch=resnet18
--batch-size=192
--epochs=1
--lr=1e-4
--gpu=0
--pretrained
--backend=sophgo_tpu
--optim=sgd
--deploy_batch_size=10
--train_data=/data/imagenet/for_train_val/
--val_data=/data/imagenet/for_train_val/
--output_path=/workspace/classify_models在上面命令输出日志中有如下图(原始onnx模型精度)中原始模型的精度信息(可与官方网页上精度进行比对以确认训练环境无误,比如官方标称:Acc@1 69.76 Acc@5 89.08,链接为:https://pytorch.apachecn.org/#/docs/1.0/torchvision_models):

完成qat训练后,跑带量化节点的eval精度,理论上在tpu-mlir的int8精度应该与此完全对齐,如下图(resnet18 qat训练精度):

最终输出目录如下图(resnet18 qat训练输出模型目录):
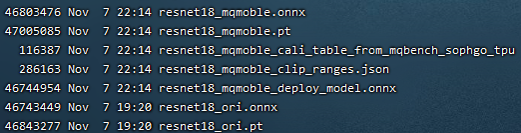
上图中带_ori的为pytorch model zoo原始pt及所转的onnx文件,将这个resnet18_ori.onnx用tpu-mlir工具链进行PTQ量化,衡量其对称和非对称量化精度作为比较的baseline。其中的resnet18_mqmoble_cali_table_from_mqbench_sophgo_tpu为导出的量化参数文件,内容如下图(resnet18 qat量化参数表样例):
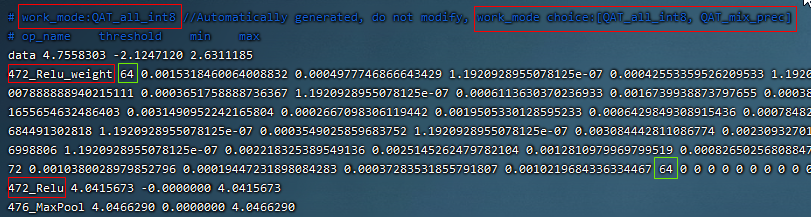
a、上图中第一行红色框内:work_mode为QAT_all_int8表示整网int8量化,可以在[QAT_all_int8、 QAT_mix_prec]中选择,还会带上量化参数:对称非对称等参数。
b、上图中472_Relu_weight表示是conv权重的经过QAT调优过的scale和zp参数,第1个64表示后面跟着64个scale,第2个64表示后面跟着64个zp,tpu-mlir会导入到top层weight的weight_scale属性中,在int8 lowering时若该属性存在就直接使用该属性,不存在就按最大值重新计算。
c、上面的min、max是非对称量化时根据激活的qat调优过的scale、zp以及qmin、qmax算出来,threshold是在对称量化时根据激活的scale算出来,两者不会同时有效。
QAT测试环境
添加cfg文件
进入tpu-mlir/regression/eval目录,在qat_config子目录下增加{model_name}_qat.cfg,比如如下为resnet18_qat.cfg文件内容:
dataset=${REGRESSION_PATH}/dataset/ILSVRC2012
test_input=${REGRESSION_PATH}/image/cat.jpg
input_shapes=[[1,3,224,224]] #根据实际shape修改
resize_dims=256,256 #下面为图片预处理参数,根据实际填写
mean=123.675,116.28,103.53
scale=0.0171,0.0175,0.0174
pixel_format=rgb
int8_sym_tolerance=0.97,0.80
int8_asym_tolerance=0.98,0.80
debug_cmd=use_pil_resize也可增加{model_name}_qat_ori.cfg文件:将原始pytorch模型量化,作为baseline,内容可以和上面{model_name}_qat.cfg完全一样;
修改并执行run_eval.py
下图(run_eval待测模型列表及参数)中在postprocess_type_all中填写更多不同精度评估方式的命令字符串,比如图中已有imagenet分类和coco检测精度计算字符串;下图(run_eval待测模型列表及参数)中model_list_all填写模型名到参数的映射,比如:resnet18_qat的[0,0],其中第1个参数表示用postprocess_type_all中第1个的命令串,第2个参数表示用qat_model_path第1个目录(以逗号分隔):
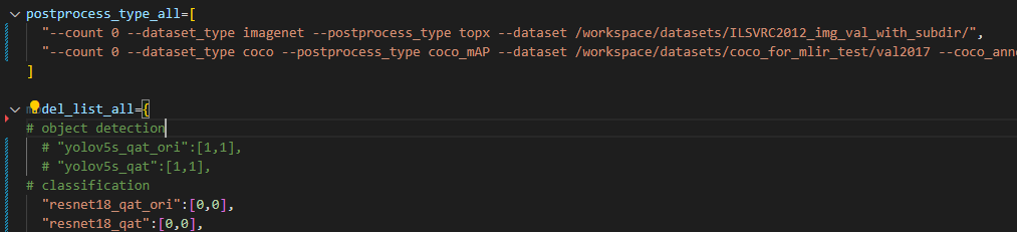
根据需要配置上图postprocess_type_all和model_list_all数组后,执行下面run_eval.py命令:
python3 run_eval.py
#qat验证模式,默认是使用tpu-mlir/regression/config中配置进行常规的模型精度测试
--qat_eval
--fast_test #正式测试前的快速测试(只测试30张图的精度),确认所有case都能跑起来
--pool_size 20 #默认起10个进程来跑,若机器闲置资源较多,可多配点
--batch_size 10 #qat导出模型的batch-size,默认为1
--qat_model_path '/workspace/classify_models/,/workspace/yolov5/qat_models' #qat模型所在目录,比如model_list_all[‘resnet18_qat’][1]的取值为0,表示其模型目标在qat_model_path的第1个目录地址:/workspace/classify_models/
--debug_cmd use_pil_resize #使用pil resize方式测试后或测试过程中,查看以{model_name}_qat命名的子目录下以log_开头的model_eval脚本输出日志文件,比如:log_resnet18_qat.mlir表示对本目录中resnet18_qat.mlir进行测试的日志;log_resnet18_qat_bm1684x_tpu_int8_sym.mlir表示对本目录中resnet18_qat_bm1684x_tpu_int8_sym.mlir进行测试的日志