CV18xx series processor currently supports ONNX and Caffe models but not TFLite models. In terms of quantization, CV18xx supports BF16 and symmetric INT8 format. This chapter takes the CV183X as an example to introduce the compilation and runtime sample of the CV18xx series processor.
If the input is an image, we need to learn the preprocessing of the model before conversion. If the model uses the preprocessed npz file as input, there is no need to consider preprocessing. The preprocessing process is expressed as follows ( \(x\) stands for input):
\[y = (x - mean) \times scale\]
The input of yolov5 on the official website is rgb image, each value of it will be multiplied by 1/255, and converted into mean and scale corresponding to 0.0,0.0,0.0 and 0.0039216,0.0039216,0.0039216.
Before converting to the INT8 model, you need to do calibration to get the calibration table. The number of input data depends on the situation but is normally around 100 to 1000. Then use the calibration table to generate INT8 symmetric cvimodel.
Here we use the 100 images from COCO2017 as an example to perform calibration:
After the operation is completed, a file named ${model_name}_cali_table will be generated, which is used as the input of the following compilation work.
To convert to symmetric INT8 cvimodel model, execute the following command:
The comparison of the four images is shown in Fig. 12.1, due to the different operating environments, the final effect and accuracy will be slightly different from Fig. 12.1.
Fig. 12.1 Comparing the results of different models
The above tutorial introduces the process of TPU-MLIR deploying the ONNX model to the CV18xx series processors. For the conversion process of the Caffe model, please refer to the chapter “Compiling the Caffe Model”. You only need to replace the processors name with the specific CV18xx processors.
For the same model, independent cvimodel files can be generated according to the input batch size and resolution(different H and W). However, in order to save storage, you can merge these related cvimodel files into one cvimodel file and share its weight part. The steps are as follows:
12.2.1. Step 0: generate the cvimodel for batch 1
Please refer to the previous section to create a new workspace directory and convert yolov5s to the mlir fp32 model by model_transform
Attention :
1.Use the same workspace directory for the cvimodels that need to be merged, and do not share the workspace with other cvimodes that do not need to be merged.
Using the above command, you can merge either the same models or different models
The main steps are:
When generating a cvimodel through model_deploy, add the –merge_weight parameter.
The work directory of the model to be merged must be the same, and do not clean up any intermediate files before merging the models(Reuse the previous model’s weight is implemented through the intermediate file _weight_map.csv).
This part introduces how to compile and run the runtime samples, include how to cross-compile samples for EVB board
and how to compile and run samples in docker. The following 4 samples are included:
Select the required files according to the processor type and load them into the EVB file system.
Execute them on the Linux console of EVB. Here, we take CV183x as an example.
Unzip the model file (delivered in cvimodel format) and the TPU_SDK used by samples. Enter into the samples directory to execute the test.
The process is as follows:
The source code is given in the released packages. You can cross-compile the samples’ source code in the docker environment and
run them on EVB board according to the following instructions.
1.1 Whether pytorch,tensorflow, etc. can be converted directly to cvimodel?
pytorch: Supports the .pt model statically via jit.trace(torch_model.eval(),inputs).save('model_name.pt').
tensorflow / others: It is not supported yet and can be supported indirectly through onnx.
1.2 An error occurs when model_transform is executed
model_transform This command convert the onnx,caffe model into the fp32 mlir. The high probability of error here is that there are unsupported operators or incompatible operator attributes, which can be fed back to the tpu team to solve.
1.3 An error occurs when model_deploy is executed
model_deploy This command quantizes fp32 mlir to int8/bf16mlir, and then converts int8/bf16mlir to cvimodel.
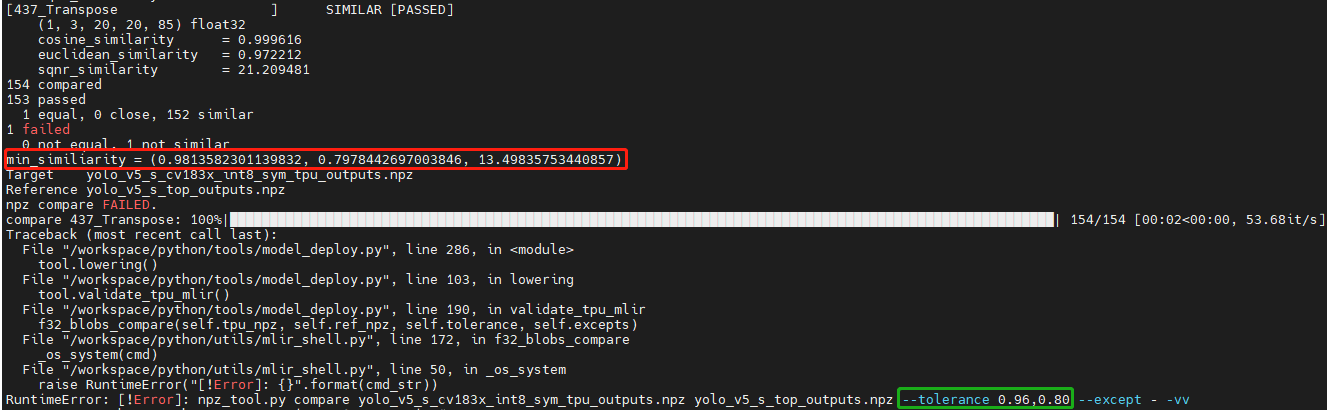
In the process of conversion, two similarity comparisons will be involved: one is the quantitative comparison between fp32 mlir and int8/bf16mlir, and the other is the similarity comparison between int8/bf16mlir and the final converted cvimodel. If the similarity comparison fails, the following err will occur:
Solution: The tolerance parameter is incorrect. During the model conversion process, similarity will be calculated for the output of int8/bf16 mlir and fp32 mlir, and tolerance is to limit the minimum value of similarity. If the calculated minimum value of similarity is lower than the corresponding preset tolerance value, the program will stop execution. Consider making adjustments to tolerance. (If the minimum similarity value is too low, please report it to the tpu team.)
1.4 What is the difference between the pixel_formatparameter of model_transform and the customization_format parameter of model_deploy?
Channel_order is the input image type of the original model (only gray/rgb planar/bgr planar is supported),customization_format is the input image type of cvimodel, which is determined by the customer and must be used together with fuse_preprocess. (If the input is a YUV image obtained through VPSS or VI, set customization_format to YUV format.) If pixel_format is inconsistent with customization_format,cvimodel will automatically converts the input to the type specified by pixel_format.
1.5 Whether the multi-input model is supported and how to preprocess it?
Models with multiple input images using different preprocessing methods are not supported.
Please check that the path of the data set is correct.
2.2 How to deal with multiple input problems by running quantization?
When running run_calibration, you can store multiple inputs using .npz, or using the –data_list argument, and the multiple inputs in each row of the data_list are separated by “,”.
2.3 Is the input preprocessed when quantization is performed?
Yes, according to the preprocessing parameters stored in the mlir file, the quantization process is preprocessed by loading the preprocessing parameters.
2.4 The program is killed by the system or the memory allocation fails when run calibration
It is necessary to check whether the memory of the host is enough, and the common model requires about 8G memory. If memory is insufficient, try adding the following parameters when running run_calibration to reduce memory requirements.
--tune_num2# default is 5
2.5 Does the calibration table support manual modification?
3.2 What is the difference in inference speed between bf16 model and int8 model?
The theoretical difference is about 3-4 times, and there will be differences for different models, which need to be verified in practice.
3.3 Is dynamic shape supported?
Cvimodel does not support dynamic shape. If several shapes are fixed, independent cvimodel files can be generated through the form of shared weights.
See Merge cvimodel Files for details.
First converted to bf16 model, through the model_tool--infoxxxx.cvimodel command to obtain the ION memory and the storage space required by the model , and then execute model_runner on the EVB board to evaluate the performance, and then evaluate the accuracy in the business scenario according to the provided sample. After the accuracy of the model output meets the expectation, the same evaluation is performed on the int8 model.
12.4.2.2. 2 After quantization, the accuracy does not match the original model, how to debug?
2.1 Ensure --test_input, --test_reference, --compare_all , --tolerance parameters are set up correctly.
2.2 Compare the results of the original model and the bf16 model. If the error is large, check whether the pre-processing and post-processing are correct.
2.3 If int8 model accuracy is poor:
Verify that the data set used by run_calibration is the validation set used when training the model;
A business scenario data set (typically 100-1000 images) can be added for run_calibration.
2.4 Confirm the input type of cvimodel:
If the --fuse_preprocess argument is specified, the input type of cvimodel is uint8;
If --quant_input is specified,in general,bf16_cvimoel input type is fp32,int8_cvimodel input type is int8;
The input type can also be obtained with model_tool--infoxxx.cvimodel
12.4.2.3. 3 bf16 model speed is relatively slow,int8 model accuracy does not meet expectations how to do?
Try using a mixed-precision quantization method. See To Mix Precision Model for details.
2.1 Add the --fuse_preprocess parameter when running model_deploy, which
will put the preprocessing inside the Tensor Computing Processor for processing.
2.2 If the image is obtained from vpss or vi, you can use --fuse_preprocess, --aligned_input when converting to the model. Then use an interface such as CVI_NN_SetTensorPhysicalAddr to set the input tensor address directly to the physical address of the image, reducing the data copy time.
12.4.3.3. 3 Are floating-point and fixed-point results the same when comparing the inference results of docker and evb ?
Fixed point has no difference, floating point has difference, but the difference can be ignored.
12.4.3.4. 4 Support multi-model inference parallel?
Multithreading is supported, but models are inferred on Tensor Computing Processor in serial.
CVI_NN_SetTensorPtr : Set the virtual address of input tensor, and the original tensor memory will not be freed. Inference copies data from a user-set virtual address to the original tensor memory.
CVI_NN_SetTensorPhysicalAddr : Set the physical address of input tensor, and the original tensor memory will be freed. Inference directly reads data from the newly set physical address, data copy is not required . A Frame obtained from VPSS can call this interface by passing in the Frame’s first address. Note that model_deploy must be set --fused_preprocess and --aligned_input .
CVI_NN_SetTensorWithVideoFrame : Fill the Input Tensor with the VideoFrame structure. Note The address of VideoFrame is a physical address. If the model is fused preprocess and aligned_input, it is equivalent to CVI_NN_SetTensorPhysicalAddr, otherwise the VideoFrame data will be copied to the Input Tensor.
CVI_NN_SetTensorWithAlignedFrames : Support multi-batch, similar to CVI_NN_SetTensorWithVideoFrame .
CVI_NN_FeedTensorWithFrames : similar to CVI_NN_SetTensorWithVideoFrame .
12.4.3.6. 6 How is ion memory allocated after model loading
6.1 Calling CVI_NN_RegisterModel allocates ion memory for weight and cmdbuf (you can see the weight and cmdbuf sizes by using model_tool).
6.2 Calling CVI_NN_GetInputOutputTensors allocates ion memory for tensor(including private_gmem, shared_gmem, io_mem).
6.3 Calling CVI_NN_CloneModel can share weight and cmdbuf memory.
6.4 Other interfaces do not apply for ion memory.
6.5 Shared_gmem of different models can be shared (including multithreading), so initializing shared_gmem of the largest model first will saves ion memory.
12.4.3.7. 7 The model inference time becomes longer after loading the business program
Generally, after services are loaded, the tdma_exe_ms becomes longer, but the tiu_exe_ms remains unchanged. This is because tdma_exe_ms takes time to carry data in memory. If the memory bandwidth is insufficient, the tdma time will increase.
12.4.4.1. 1 In the cv182x/cv181x/cv180x on-board environment, the taz:invalid option –z decompression fails
Decompress the sdk in other linux environments and then use it on the board. windows does not support soft links. Therefore, decompressing the SDK in Windows may cause the soft links to fail and an error may be reported
12.4.4.2. 2 If tensorflow model is pb form of saved_model, how to convert it to pb form of frozen_model
importtensorflowastf
fromtensorflow.keras.applications.mobilenet_v2importMobileNetV2
fromtensorflow.keras.preprocessingimportimage
fromtensorflow.keras.applications.mobilenet_v2importpreprocess_input,decode_predictions
importnumpyasnp
importtf2onnx
importonnxruntimeasrt
img_path="./cat.jpg"# pb model and variables should in model dirpb_file_path="your model dir"img=image.load_img(img_path,target_size=(224,224))x=image.img_to_array(img)x=np.expand_dims(x,axis=0)# Or set your preprocess herex=preprocess_input(x)model=tf.keras.models.load_model(pb_file_path)preds=model.predict(x)# different model input shape and name will differentlyspec=(tf.TensorSpec((1,224,224,3),tf.float32,name="input"),)output_path=model.name+".onnx"
model_proto,_=tf2onnx.convert.from_keras(model,input_signature=spec,opset=13,output_path=output_path)