TPU-MLIR Introduction
TPU-MLIR is the TPU compiler project for AI chips. This project provides a complete toolchain, which can convert pre-trained neural networks under different frameworks into binary files bmodel that can be efficiently run on TPUs. The code has been open-sourced to github: https://github.com/sophgo/tpu-mlir .
The overall architecture of TPU-MLIR is shown in the figure (TPU-MLIR overall architecture).
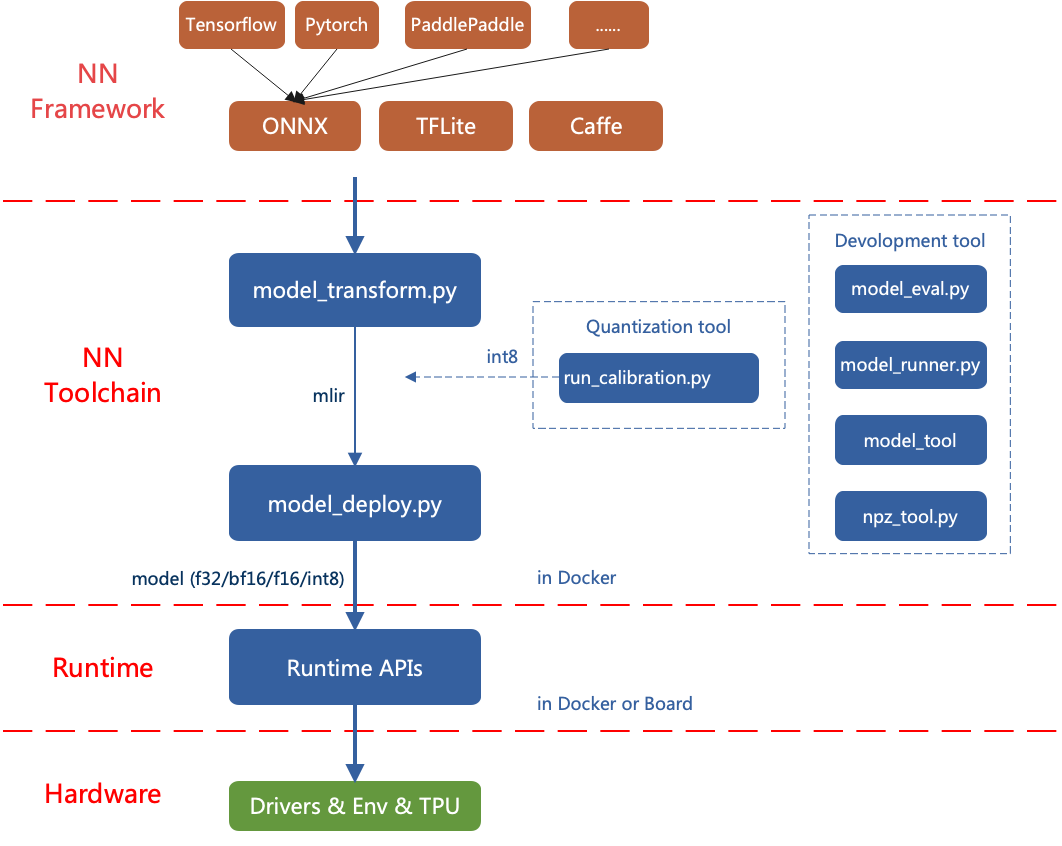
The current directly supported frameworks are pytorch, onnx, tflite and caffe. Models from other frameworks need to be converted to onnx models. The method of converting models from other frameworks to onnx can be found on the onnx official website: https://github.com/onnx/tutorials.
To convert a model, firstly you need to execute it in the specified docker. With the required environment, conversion work can be done in two steps, converting the original model to mlir file by model_transform.py and converting the mlir file to bmodel by model_deploy.py. To obtain an INT8 model, you need to call run_calibration.py to generate a quantization table and pass it to model_deploy.py. This article mainly introduces the process of this model conversion.