TPU-MLIR 的整体架构,就是将原始模型转为处理器无关层的 mlir 模型,经过图优化后再下沉到处理器相关层,然后在处理器相关层里经过一系列的优化操作最终生成能够在 tpu 上运行的二进制模型。
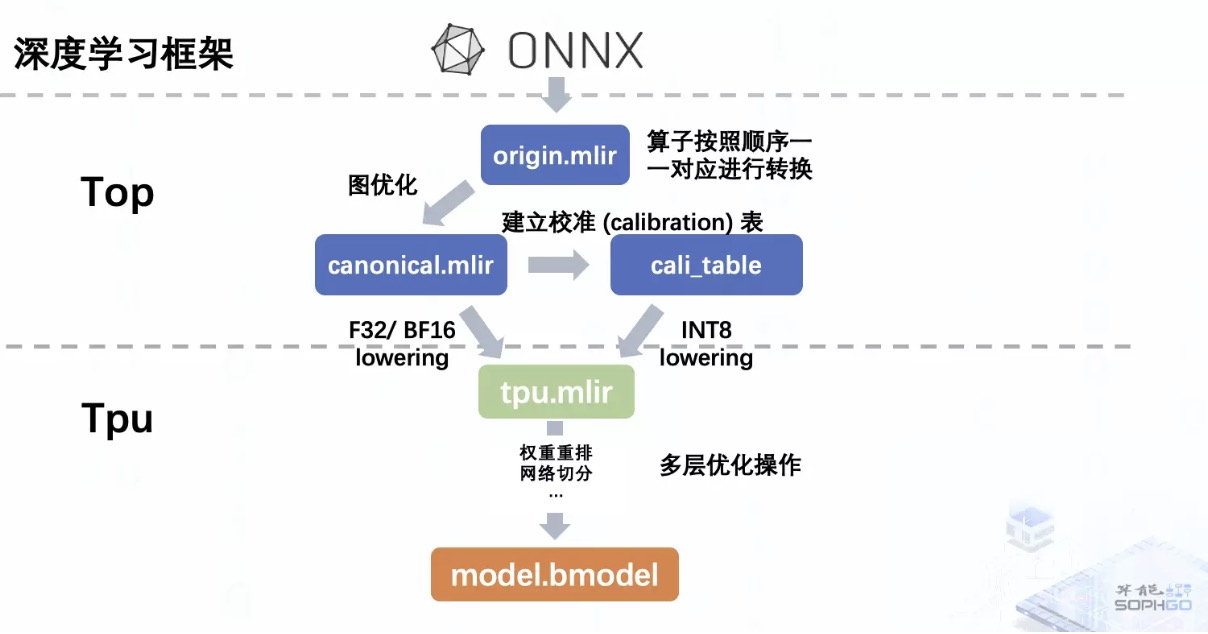
而前端转换在整个架构里面承担的就是初步的模型转换工作,也就是将原始模型转为 Top 层模型,但这个过程并不包含算子优化部分,所以它其实就是照本宣科地按照原模型的结构来生成 MLIR 文件。最终我们会得到一个初始的 mlir 文件以及存放模型权重的 npz 文件。
在 TPU-MLIR 中,整个前端的工作流程其实可以分为前提,输入,初始化 Converter,生成 mlir 文本,输出结果这五个步骤。
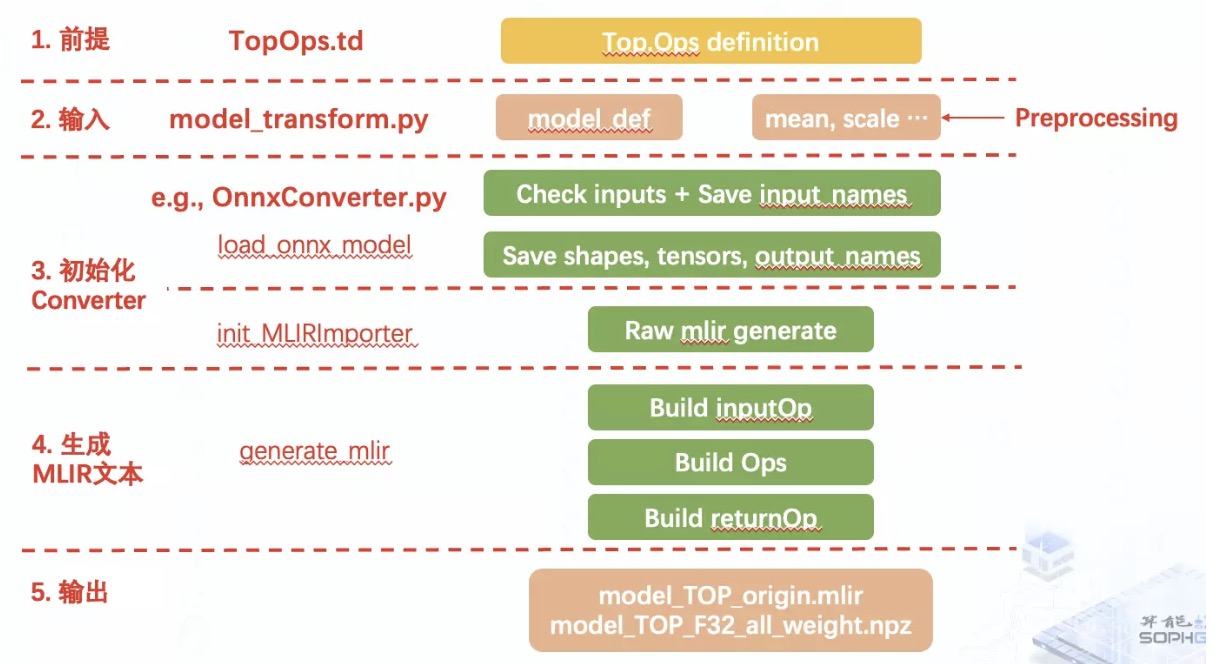
其实模型转换本质上就是对模型中每个算子进行转换,所以在将模型转换为某个 Dialect 中的 IR 前,就需要先在相应的 td 文件中对每个 Op 进行定义;
接着我们通过 model_transform.py 接口输入原始模型以及预处理参数,通常我们可以在每个模型的官网上查看到它的预处理信息;
根据输入的模型类型我们会调用针对该深度学习框架的 Converter 来加载模型,提取模型转换所需的信息用于后续的 mlir 算子创建,以及初始化 mlir 模型;
接着我们通过遍历整个原模型,加上前一步中获得的信息,便可以在初始的 mlir 文本中按照原模型的结构逐一插入算子,生成完整的 mlir 模型;
最后将结果保存在对应的文件中,便完成了前端转换流程。
在 Converter 初始化中主要提取的信息有模型的输入与输出名称,各个算子的输出形状以及算子中带有的权重,而初始的 mlir 模型其实就是只包含 moduleOP 与 main function Op 的文本。
在遍历原始模型时,会与原模型一一对应地创建 Op,然后按顺序插入到 mlir_module 中,并且将对应的 Op result, 也就是操作数保存在 operands 字典里,方便在创建后续 op 时作为输入。
其中,如果中间算子带有权重,我们还会额外为其创建 weightOp,weightOp 也会作为带权重算子的输入之一,所以它也会作为操作数被加入到 operands 字典里。
接下来我们以一个简单的 ONNX 卷积网络作为例子进行前端转换,首先我们会在 Top 层的 td 文件里定义 Conv 算子,这个定义中的 Value 部分就是我们之后在创建 mlir 的 Conv 算子时需要获取的操作数以及这个 op 会输出的 op result,Attr 部分是我们需要从 onnx 算子中获取的属性。
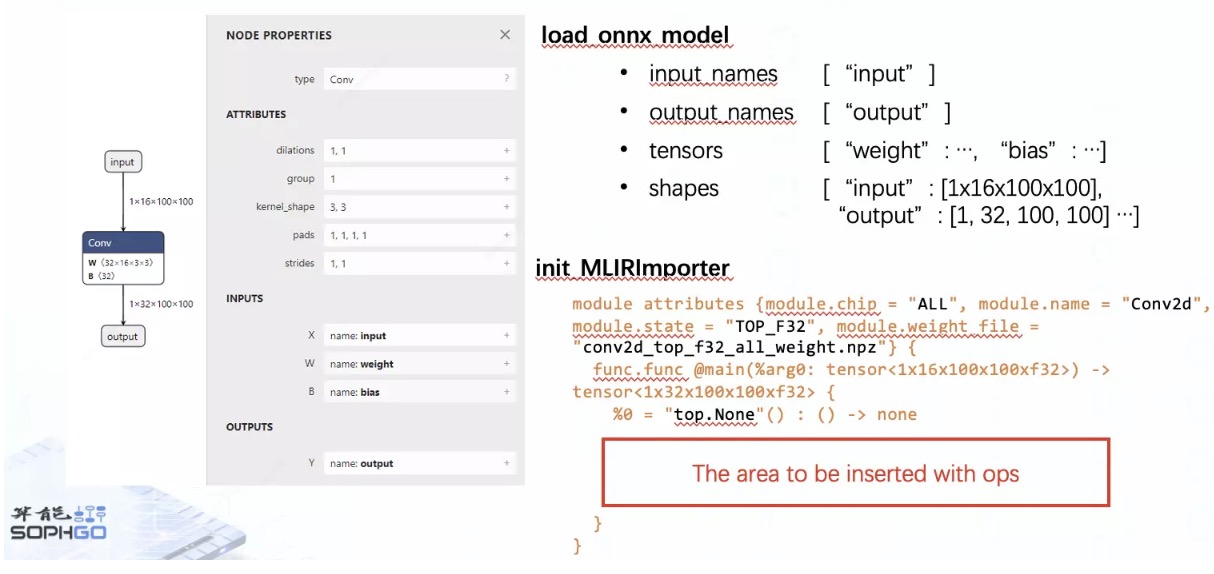
在 load_onnx_model 阶段我们从原模型获取了所需的信息,然后在 init_MLIRImporter 阶段初始化了 mlir 模型,接着我们开始遍历整个卷积模型,逐一创建并把对应的 Op 插入到 mlir 文本里。
首先是根据 input_names,shapes 中的信息创建并插入了 inputOp,如果我们转换的是一些带有预处理信息,较为复杂的 CV 模型,我们这里还需要读取输入阶段的预处理参数。
当碰到 Conv 这个带有 weight 与 bias 权重的中间算子时,会先创建对应的 weightOp,插入到 mlir 文本中并把操作数添加到 operands 里,接着再创建 ConvOp 并重复相同的插入操作。
完成遍历后根据 output_names 列表中的输出名称获取对应的操作数,创建并插入 returnOp,注意这个 returnOp 较为特殊,主要是为了在结尾指明模型的输出都有哪些,所以并不会被加入到 operands 字典里,至此便完成了整个前端转换流程。