什么是量化#
我们在前期的视频中提到过,随着深度学习的发展,为了达到更好的效果,神经网络的规模越来越大,所需的内存与计算量也就越大,这导致模型部署的难度也随之增加。
所以为了实现大型模型的部署,除了使用高性能的专用处理器外,另一个方式就是进行模型压缩,而量化就是模型压缩的一种方式,使模型实现轻量化并一定程度上提升模型在硬件上的推理效率。
量化的本质其实就是将权重与激活值由 32 位浮点型表示的范围很大的数值映射到由较低位固定点表示的小范围内,例如比较广泛应用的 8 位整形 int8。
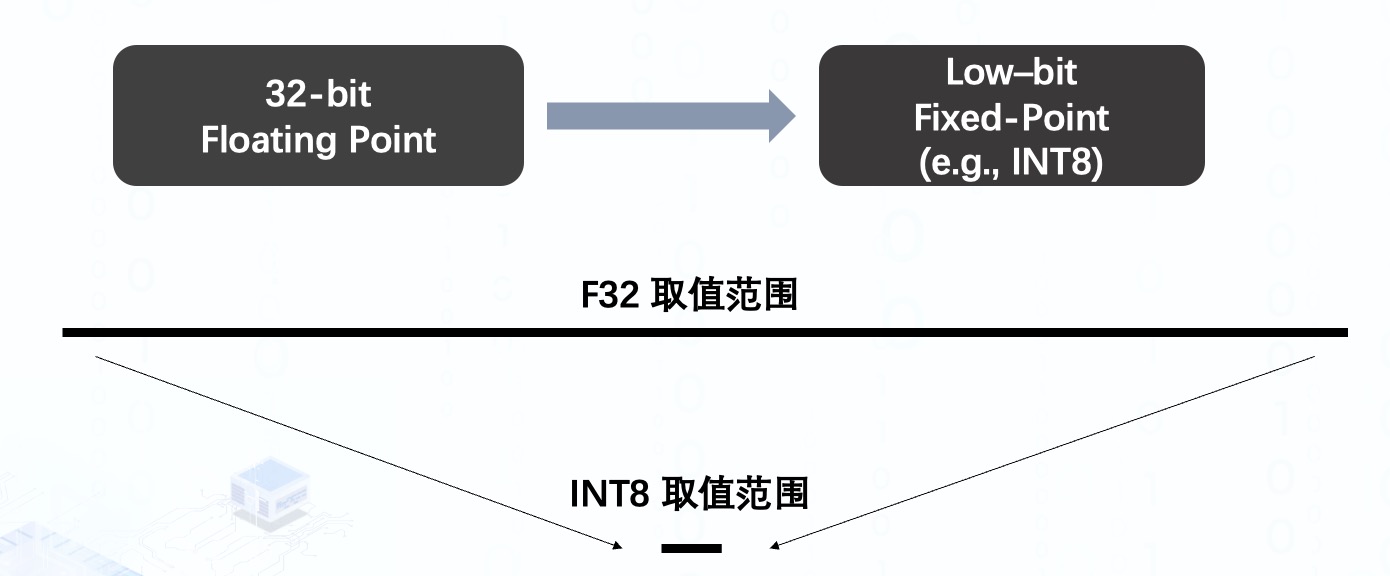
那么这样的做法为什么有效呢?除了最直观的降低权重所占的内存外,主要还是跟模型在硬件上的推理过程有关。
为什么要量化#
以深度学习模型中常见的卷积运算为例,我们知道卷积可以看做是矩阵的运算过程。
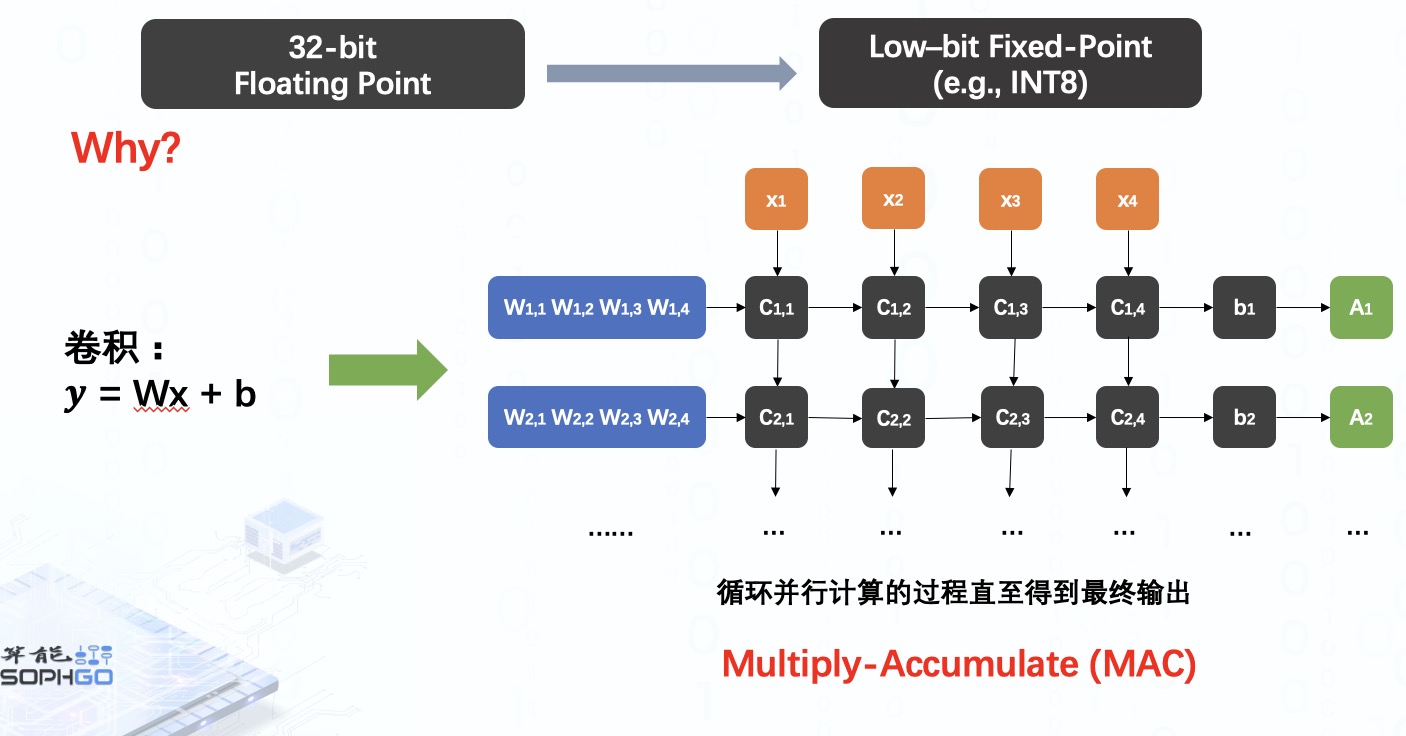
而每个卷积核与输入的运算是相互独立的,所以在硬件上运行时,我们会通过并行计算同时计算出多个卷积核的运算结果,再将它们连同 bias 一起累加起来。我们会循环这个并行计算的过程直至得到最终的输出结果,这样的操作我们称为 MAC。
而对于 MAC 来说,数字运算成本通常与数据的位数呈二次线性关系,所以采用低位的数据进行运算的成本要更低。
另外,当我们在要硬件上进行运算的时候还需要有一个 data transfer 的过程,将数据从内存转移到处理器上,运算结束后又要将其存回内存中等着被神经网络的下一层运算使用。显然,低位数据在这个过程中的搬运效率肯定是更高的。
因此,结合了这两个方面的优势,模型的整体推理效率也就得到了提高,但是因为采取了低位的表达方式,在运算过程中不可避免地会损失掉一些信息,导致一部分精度的损失。
当前针对模型的量化普遍分为两种形式:训练后量化与量化感知训练。
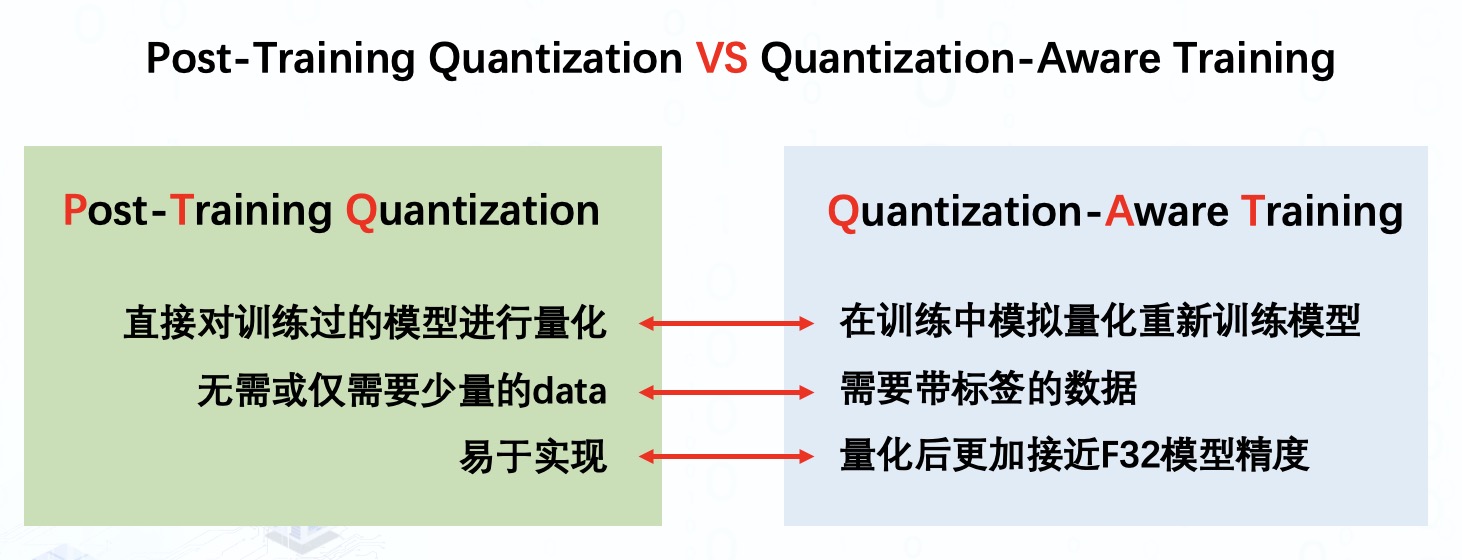
训练后量化顾名思义,就是直接对预训练过的模型进行量化操作,这个过程中可能会用到少量的 data,但不需要对模型进行重新训练。显然,这种量化类型易于较快地在各种模型上实现。
而量化感知训练则是在训练中模拟量化重新训练网络,所以需要额外的 data 对网络进行 fine-tune,整体过程较为繁琐,但是量化后的网络精度通常能够更加接近于原模型精度。
整体来说,所以两种方式都各有优缺点,而在具体的量化方案上,最常被用到的就是 uniform quantization,也就是均匀量化,这里又分为对称与非对称两种量化类型,其中对称量化下又分为有符号与无符号两种类型。
量化方案又会随着模型精度与实现难易度的权衡而变化,对于量化方案:对称量化,非对称量化,以及量化策略:MinMax, KLD, ADMM, EQ 等,后续会继续讲解。