Lowering 的作用#
从高级语言过渡到低级的机器码,在 MLIR 中是通过 Lowering(降低)来实现的。
在上期视频中我们提到 MLIR 的 dialect conversion 是指 IR 在不同 dialect 间进行转换的过程,而 lowering 其实就是从 high-level dialect 到 low-level dialect 的 dialect conversion。
以 TPU-MLIR 为例,lowering 在其中扮演的作用就是将处理器无关层的 mlir 模型转换到处理器相关层。
模型的转换其实本质上就是算子的转换,Top 层的算子可以分为 F32 与 INT8 两种,大多数网络中算子都是 F32 的,部分如 tflite 等量化过的网络存在 INT8 算子。
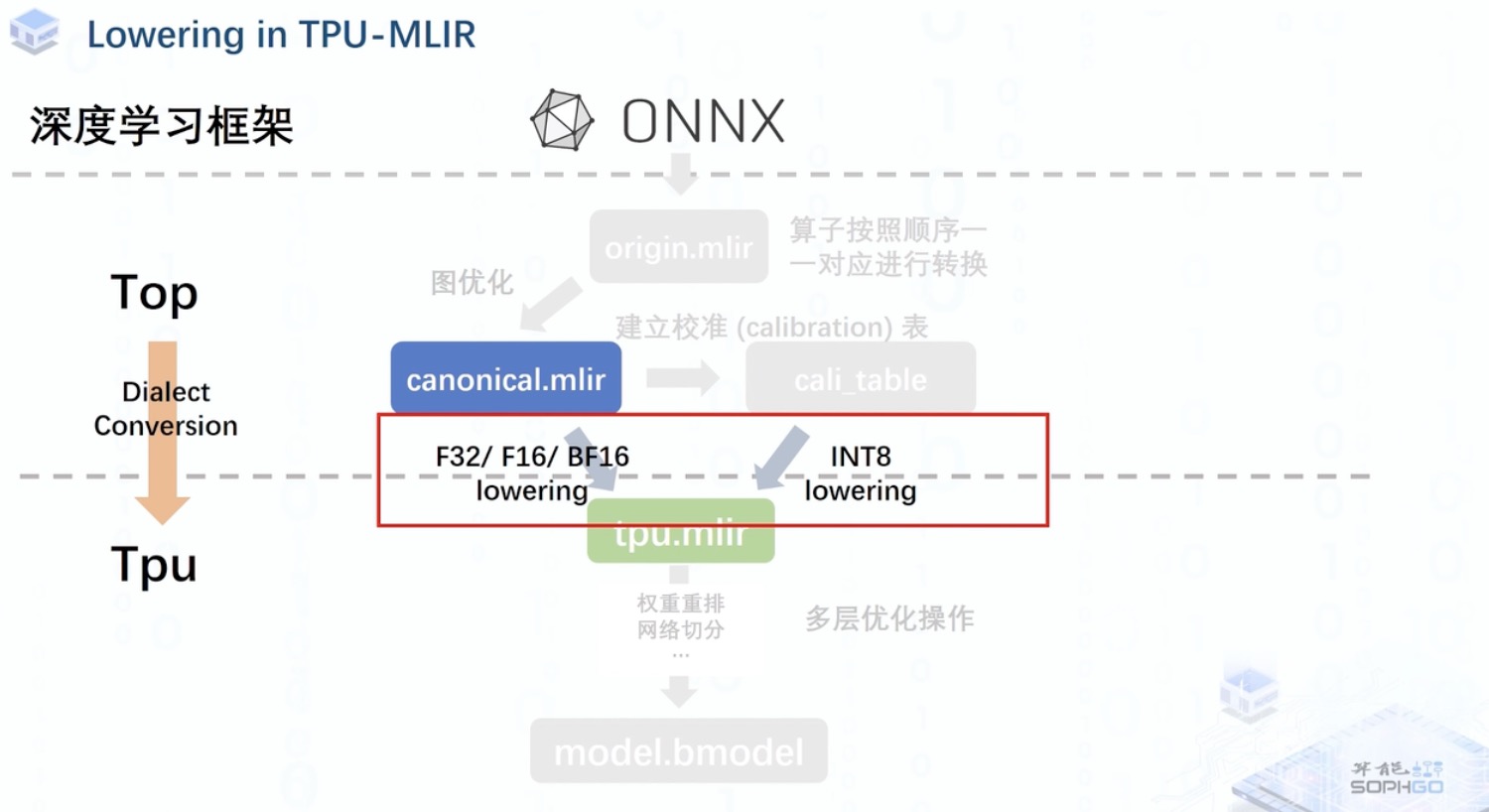
Top 层的 F32 算子可以被直接转换为 F32,F16 或 BF16 的 tpu 层算子,如果要转换为 int8 算子,则需要经过校准量化,而 int8 的 top 层算子则只能转换为 int8 的 tpu 层算子
另外,在进行混合精度运算,也就是前后算子的类型不一致时,为了保持运算精度相同,TPU-MLIR 会在算子间插入 CastOp 对算子的输出类型进行转换。
如何实现 Top 层到 Tpu 层的转换过程?#
- 首先我们就需要对目标 dialect 以及转换 pass 进行定义, 这些定义我们都可以在 td 文件中完成,其中 ConvertTopToTpu pass 定义中的 mode 指的是对总体算子的量化模式 F32/INT8/F16/BF16。而 qtable 则用来明确模型中某一层算子的量化模式,使用 qtable 就可能会产生我们之前提到的前后算子类型不一致的情况,这时候就需要插入 CastOp 来帮助混合精度运算的实现。processor 则是指定需要 lower 到的特定处理器,当 mode 为 int8 时,又存在对称与非对称 int8 量化两种情况,所以即使都在同一层 dialect 里,转换过程与最终生成的 IR 也会根据 option 里的内容不同而有所不同。

- 之后我们由 OpRewritePattern 派生一个 TopLowering 类来定义算子 rewrite 的逻辑,类中定义的一系列虚函数用于将算子 lowering 到某个特定处理器上时被实现,例如我们可以在 LoweringBM1684X 头文件中看到,下降到 BM1684x 处理器的中所需实现的量化模式。
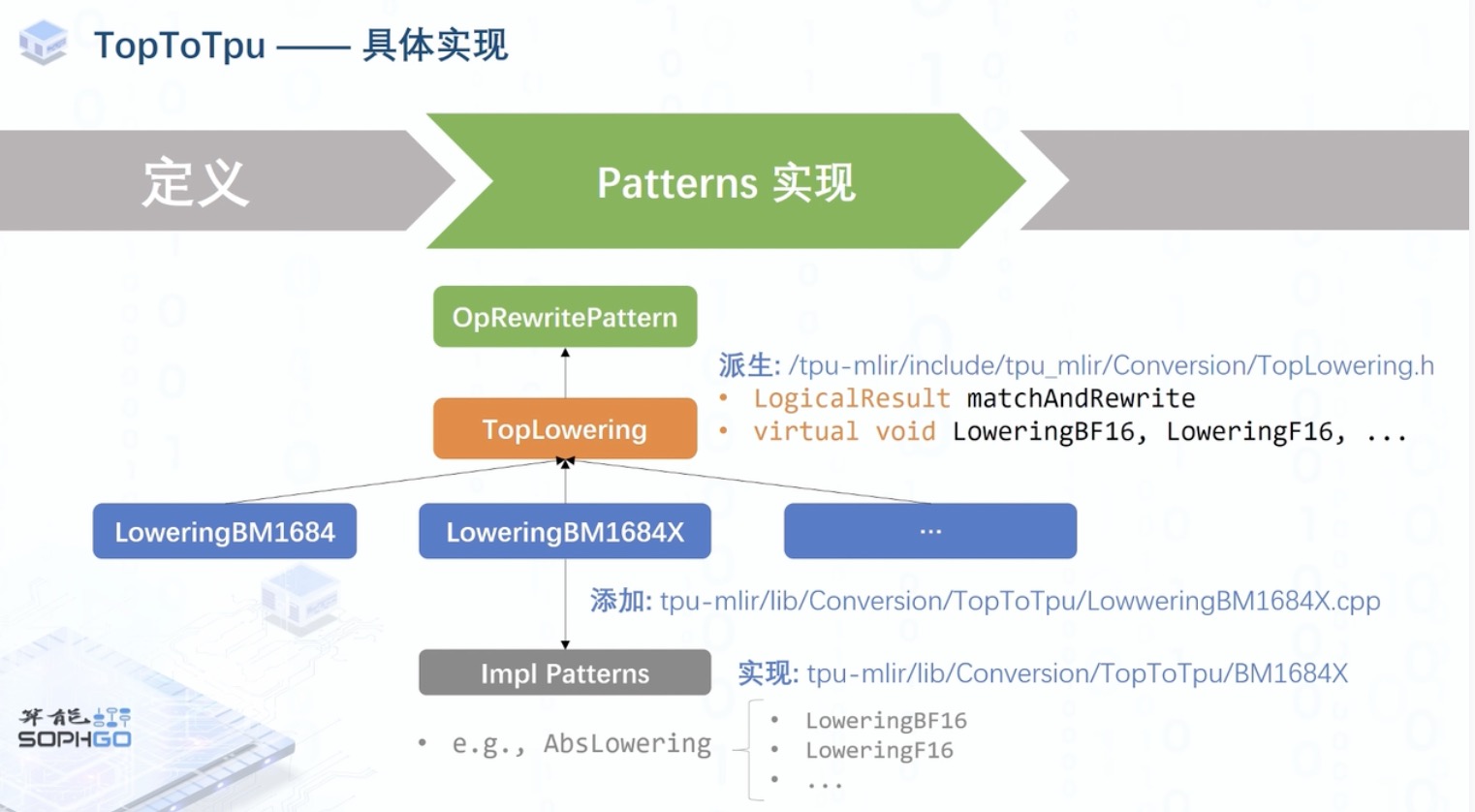
之后针对每个 BM1684X 所支持的算子我们需要实现相应的 pattern,而每个 pattern 中就包含了不同量化模式的具体 lowering 实现
- 接下来就是实现 pass 中的功能,大致的流程也与我们这期视频中提到的相同。
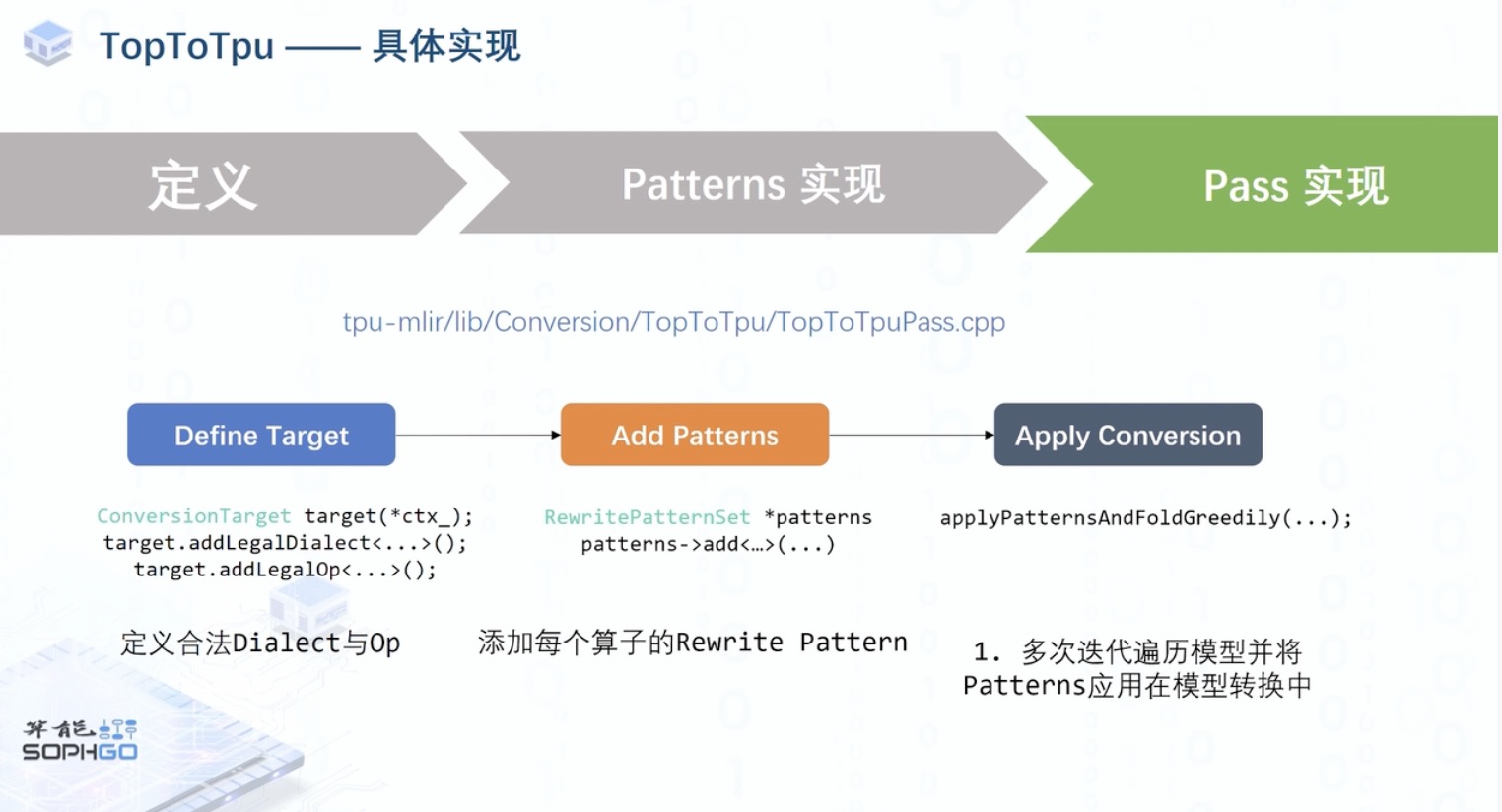
- 首先就是定义合法的 dialect 与 op,在转换时我们会保留这些合法的 op
- 然后根据目标处理器与算子的量化类型添加相应的 rewrite pattern
- 最后通过转换接口迭代地遍历 Top 层模型并将相应的 patterns 应用到转换过程中。另外,这个转换过程并不会只进行一次,我们会在整个流程中多次添加不同的 patterns,进行转换,然后清空 patternSet,为下一次转换做准备。
- 在转换结束后,我们还会对转换过后的模型进行类型验证,并在相应的位置添加 CastOp 以应对混精度的情况。
- 至此,整个 Top 层到 Tpu 层的 lowering 流程结束