The video tutorial of TPU-MLIR open-source AI compiler has been synchronously updated on bilibili, Zhihu and CSDN, aiming to let the audience gradually understand the principle and development of AI compiler through a series of courses.
Video sharing is mainly based on TPU-MLIR, an open-source toolchain of SOPHGO. The content will cover the basic syntax of MLIR and the implementation details of various optimization in the compiler, such as graph optimization, int8 quantization, operator segmentation and address allocation.
Main functions of AI compiler: simplify network construction and network performance improvement#
Traditional compilers in computers can convert various high-level languages such as C++, Python and other programming languages into unified low-level languages that can be understood by computers. In essence, AI compilers are quite similar to traditional compilers, except that the objects to be converted become networks built and trained by various deep learning frameworks, also known as computational graphs. The small computational modules that build the graphs, such as relu and pooling, are also called operators.
Obviously, users can program more efficiently through high-level languages, and the work of language conversion can be directly handed over to the compiler. The main difference between traditional compilers and AI compilers is that the main purpose of the former is to reduce the difficulty of programming. Although AI compilers also play a role in simplifying the difficulty of network construction, their main function is to improve network performance.

GPU, as a graphics processor, has certain limitations in AI computing. For example, the operation of GPU depends on the call of CPU, and the running of classical computers based on the existing von Neumann architecture will inevitably be limited by the separation of storage and computing, thus affecting the overall working efficiency.
TPU is a tensor processor specially used for artificial intelligence algorithms. However, if users want it to play a more efficient role, the AI compiler needs to serve as an intermediate bridge. Please watch the detailed video course on how the AI compiler can improve the computing efficiency of TPU.
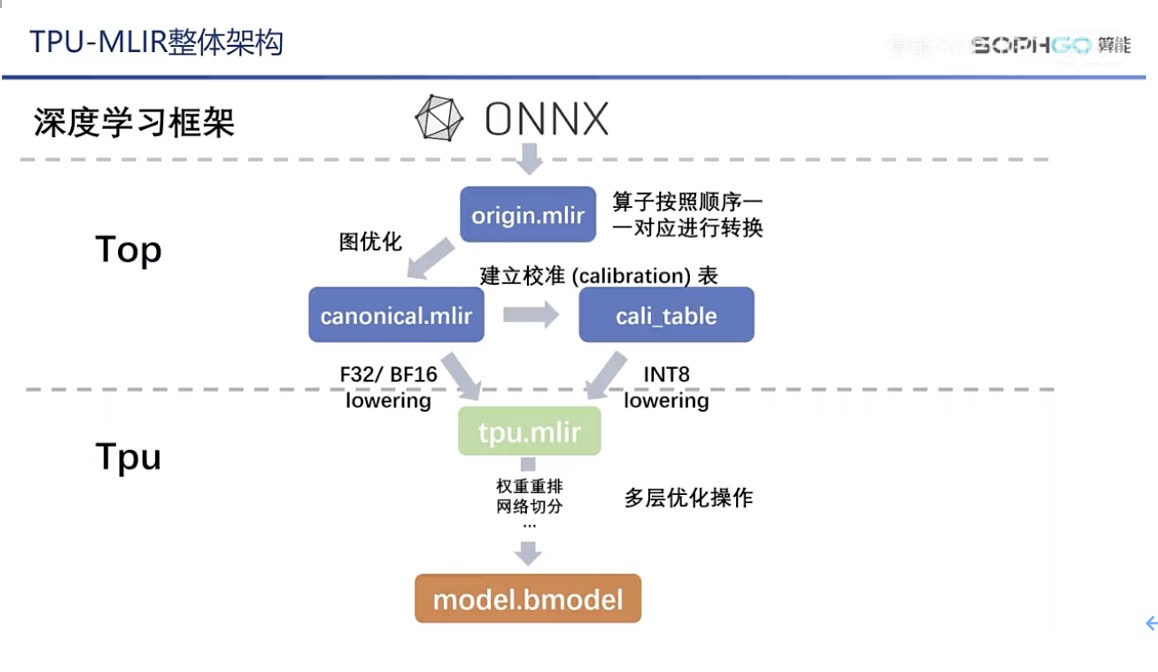
As there are few teaching resources related to MLIR and AI compilers in China, problems cannot be solved effectively. The supporting video courses of TPU-MLIR will be a good supplement. TPU-MLIR developers will also patiently answer questions from community users.
Video Tutorial:
https://live.csdn.net/v/241401?spm=1001.2014.3001.5501
Perfect community support. TPU-MLIR developers can answer readers’ questions#
Q: At present, TPU-MLIR only supports 1684x chips. Does this mean that the current compiler project is only valid for the current processor architecture?
A: Not quite. The development team has done a lot of optimizations on the TPU layer to further improve the performance of the model. Although it is aimed at the 1684x implementation, the same operations can also be applied to other chips. There are some adjustments in the implementation, so it has great reference significance for building a more universal AI compiler.
Q: The open-source project of TPU-MLIR is based on the docker environment. Can the reasoning results run in the docker represent the real running results on the processor?
A: The TPU processor is mainly to improve the performance of the model. The accuracy is mainly determined by the model itself and the conversion process. Theoretically, the accuracy of the model will decline slightly during the conversion process. The better the toolchain is implemented, the less the loss of accuracy in this process. What we do in Docker is compare the accuracy of the original and converted models. If the difference is small, it can ensure the actual operation effect on the processor.
Q: How does the compilation toolchain support models written by TensorFlow, PyTorch, Caffe and other frameworks?
A: Now the main steps to support the new model are:
- Write the corresponding operator conversion method according to the original model
- Input the original model into our user interface to try to convert the model
- Solve problems during model adaptation
- Compare the output results of each operator of the original and transformed models
- Identify and solve potential problems according to different output results
Q: We know that TPU processor can accelerate AI training and reasoning. What are the main processes to accelerate?
A: The essence of TPU processor acceleration is to split a model into operators, convert each operator, and finally turn them into instructions that can be understood by our processor. The essence of the model is that data is operated between operators, then transferred to the next operator, and finally output the results.
AI compiler is a complex project, but our TPU-MLIR team will work with many developers to create a set of extensible, high-performance AI compiler tools that can be used for reference by the industry.