Recently, the TPU-MLIR open-source compiler team has welcomed new blood. After multiple selections, five new students from well-known universities at home and abroad were finally shortlisted. They will work with core developers to optimize TPU-MLIR.
The development of TPU-MLIR is also in full swing. Recently, Caffe framework support, operator optimization and other aspects have been updated:
- Add more complex operators, such as LSTM;
- Optimization of some operators and support for more situations, such as the broadcast operation of Add and Mul operators;
- Previously, TPU-MLIR mainly supported int8 quantization. FP16/BFP16 quantization is now gradually improved;
- Caffe framework support: ResNet and MobileNet have been supported;
The website of TPU-MLIR has also been officially launched. To better support global developers, the Chinese and English versions of the development documents have been updated simultaneously!

New members’ idea on TPU-MLIR: fully consider the hardware characteristics and accurately grasp the design principles of MLIR core#
TPU-MLIR is built based on MLIR. A thorough understanding of the underlying principles of MLIR is of great help to the development.
MLIR (Multi-Level Intermediate Representation) is a general and reusable compiler framework, which provides a series of reusable and extensible basic components for building domain-specific compilers. But since it was originally developed for TensorFlow of Google, it has its tensor type, which is more adaptive to development related to machine learning than its predecessor LLVM, which only has fixed length vector.
In terms of design, compared with the integrity and strong coupling of LLVM, MLIR emphasizes component and decoupling. In the face of high-level abstract problems such as machine learning, MLIR can lower the complexity of the problem layer by layer in a discrete way. One of the reasons is that MLIR introduces the concept of Dialect.
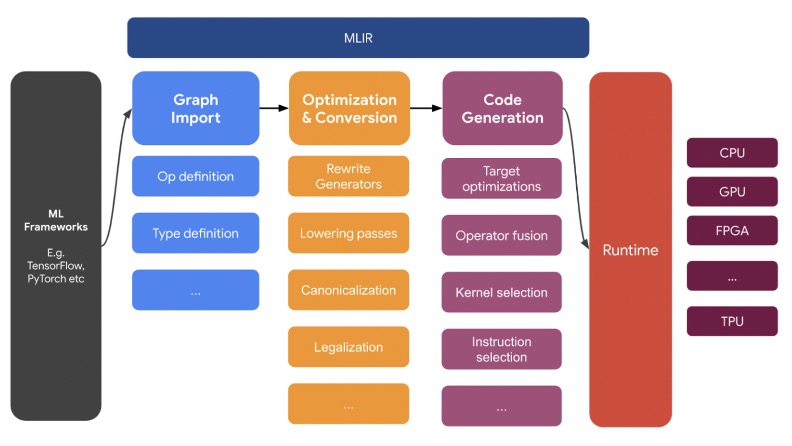
From the perspective of IR, TPU-MLIR is mainly divided into two Dialects: Top Dialect and TPU Dialect. Top Dialect is a high-level abstraction that is independent of the bottom layer. Optimization at this level is also independent of the hardware, such as operator fusion and quantization. TPU Dialect contains the details of the underlying hardware, and its optimization also fully considers the characteristics of the hardware, such as memory management.
This design reflects the core principle of MLIR: hierarchical IR design, in which user programs are gradually transformed from high-level abstractions to low-level abstractions, and finally into code that can be implemented by hardware. The advantage of this design is that each layer can focus on the optimization and improvement of a single layer, without considering too many details of other layers.
For TPU-MLIR, the new members also put forward some suggestions on optimization. For example, the currently supported frameworks are TFLite and ONNX. Later, they can directly convert other framework models to reduce the workload of handwriting loss operators.
Community influence is emerging, and TPU-MLIR is recognized by GitHub developers#
The project leader of TPU-MLIR also answered many questions. He added two points about multi-processor support and model quantification:
First, TPU-MLIR supports the conversion of AI models to specific chips for reasoning and running. Currently, it only supports 1684x. Recent development tasks will not involve too many processor details. He hopes that everyone can learn some general knowledge on AI compilers;
Second, TPU-MLIR supports floating-point mode and INT8 mode. Generally, the performance of INT8 mode is more than 8 times that of the floating-point model, so INT8 mode will be the mainstream of inference processor. The conversion from floating-point to INT8 is called “quantization”.
Why quantify? Compared with FP32, the low precision INT8 computing has a slight impact on the accuracy of the algorithm, but it brings a huge improvement in computing power, which is suitable for many edge scenarios.
As an open-source practice of MLIR in the design direction of the ASIC toolchain, TPU-MLIR has also been recognized by community developers. From the top-level architecture design to the details of implementation, there are detailed guiding documents for users’ reference.
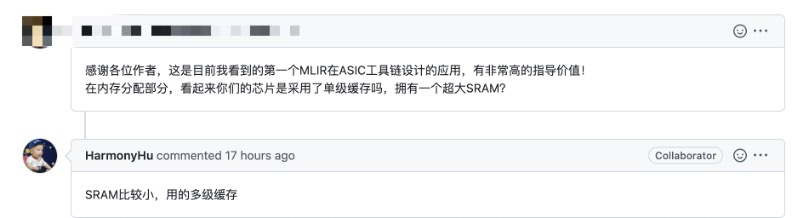
In just one month of open source, the number of stars on GitHub has reached 115, which is not easy for a compiler project with bottom-level development.
If you are also interested in MLIR and compiler development, welcome to join the TPU-MLIR development work. Submit the project PR and experience the landing of your code in the real scenario!