18. Implementing Backend Operators with PPL
PPL (Programming Language for TPUs) is a domain-specific programming language (DSL) based on C/C++ syntax extensions, designed for programming Tensor Processing Units (TPUs). This chapter demonstrates how to implement backend operators in PPL using the add_const_fp operator as an example, illustrating the compilation and utilization of PPL code within TPU-MLIR.
The implementation of PPL backend operators can be found in the tpu-mlir/lib/PplBackend/src directory. For release packages, it will be located in the PplBackend/src directory of the TPU-MLIR release package. For detailed instructions on writing PPL source code, refer to the documentation in tpu-mlir/third_party/ppl/doc.
18.1. How to Write and Call Backend Operators
Step 1: Implement Three Source Files
You need to create three source files: one for the device-side pl code, one for the host-side cpp code, and another for the host-side tiling function cpp code. . For the add_const_fp example, these files are:
add_const_fp.pl: Implements theadd_const_f32,add_const_f16andadd_const_bf16, etc kernel interfaces.add_const_fp_tile.cpp: Implements theadd_tilingfunction to call these kernel interfaces.add_const_fp_api.cpp: Implements theapi_add_const_fp_globalfunction to call theseadd_tilinginterfaces.
tiling.cpp File Example
// Include the automatically generated header file from the pl file #include "add_const_fp.h" // Include the header file for MLIR data types and structures #include "tpu_mlir/Backend/BM168x/Param.h" // The entry function must be defined using extern "C" extern "C" { // If the pl file provides multiple operators, you can define function pointers in advance. // This can help reduce repetitive code. Note that the pointer type in the pl file // needs to be defined using `gaddr_t`. using KernelFunc = int (*)(gaddr_t, gaddr_t, float, int, int, int, int, int, bool); // Add the entry function with user-defined input parameters int add_tiling(gaddr_t ptr_dst, gaddr_t ptr_src, float rhs, int N, int C, int H, int W, bool relu, int dtype) { KernelFunc func; // Select the appropriate operator based on the input data type if (dtype == DTYPE_FP32) { func = add_const_f32; } else if (dtype == DTYPE_FP16) { func = add_const_f16; } else if (dtype == DTYPE_BFP16) { func = add_const_bf16; } else { assert(0 && "unsupported dtype"); } // Calculate the block size. Align the block size to `EU_NUM` to reduce memory allocation failures. // Since most of the memory on the TPU is aligned to `EU_NUM`, this alignment will not affect memory allocation. int block_w = align_up(N * C * H * W, EU_NUM); int ret = -1; while (block_w > 1) { ret = func(ptr_dst, ptr_src, rhs, N, C, H, W, block_w, relu); if (ret == 0) { return 0; } else if (ret == PplLocalAddrAssignErr) { // If the error type is `PplLocalAddrAssignErr`, it means the block size is too large, // and the local memory cannot accommodate it. The block size needs to be reduced. block_w = align_up(block_w / 2, EU_NUM); continue; } else if (ret == PplL2AddrAssignErr) { // If the error type is `PplL2AddrAssignErr`, it means the block size is too large, // and the L2 memory cannot accommodate it. The block size needs to be reduced. // In this example, L2 memory is not allocated, so this error will not occur. assert(0); } else { // Other errors require debugging assert(0); return ret; } } return ret; } }
Notes
The add_const_fp.h header file contains some error codes and chip-related parameter definitions.
The pointers in the pl file need to be defined using the gaddr_t type.
Parameter Name |
Description |
|---|---|
PplLocalAddrAssignErr |
Local memory allocation failed |
FileErr |
|
LlvmFeErr |
|
PplFeErr |
AST to IR conversion failed |
PplOpt1Err |
Optimization pass opt1 failed |
PplOpt2Err |
Optimization pass opt2 failed |
PplFinalErr |
Optimization pass final failed |
PplTransErr |
Code generation failed |
EnvErr |
Environment variable exception |
PplL2AddrAssignErr |
L2 memory allocation failed |
PplShapeInferErr |
Shape inference failed |
PplSetMemRefShapeErr |
|
ToPplErr |
|
PplTensorConvErr |
|
PplDynBlockErr |
Parameter Name |
Description |
|---|---|
EU_NUM |
Number of EUs |
LANE_NUM |
Number of lanes |
Step 2: Call the Kernel Interface
In the function void tpu::AddConstOp::codegen_global_bm1684x() within lib/Dialect/Tpu/Interfaces/BM1684X/AddConst.cpp, call api_add_const_fp_global as follows:
BM168x::call_ppl_global_func("api_add_const_fp_global", ¶m,
sizeof(param), input_spec->data(),
output_spec->data());
If the operator supports local execution, implement api_xxxxOp_local and call it using BM168x::call_ppl_local_func.
BM168x::call_ppl_local_func("api_xxxx_local", &spec, sizeof(spec),
&sec_info, input_spec->data(),
output_spec->data());
This completes the implementation of the backend operator.
18.2. PPL Workflow in TPU-MLIR
Place the PPL compiler in the
third_party/ppldirectory and update it by referring to the README.md file in this directory.Integrate the PPL source code compilation in
model_deploy.py. The process is illustrated in the following diagram:
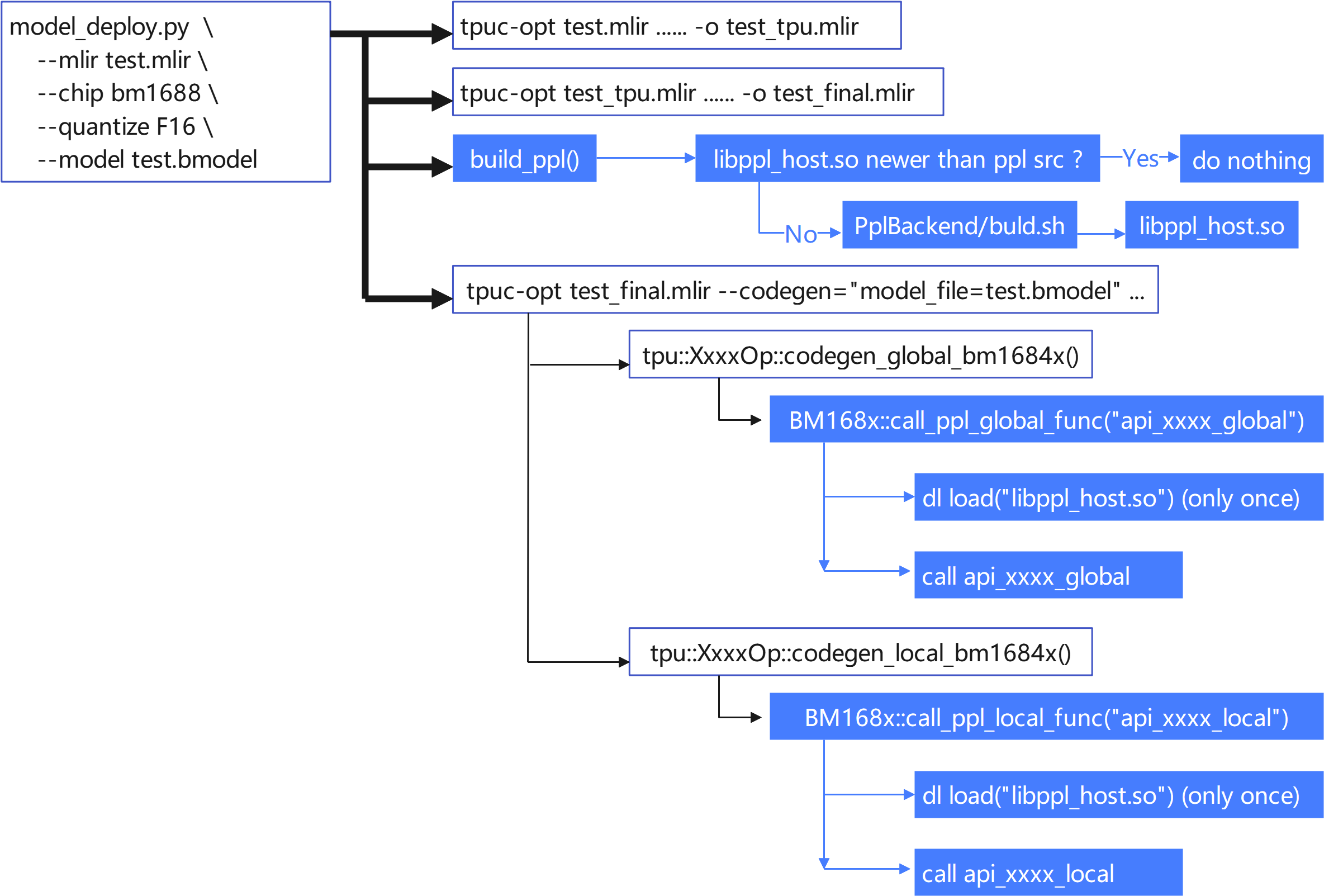
Fig. 18.1 PPL Workflow