模型
视觉、语音、大语言模型 — 都跑在 TPU 上。
以下并非完整清单,仅为 TPU-MLIR 回归与示例流程中常见的代表性模型族。
视觉
★YOLOv5
★YOLOv8
ResNet
MobileNet
SAM
Stable Diffusion
语音
★Whisper
Paraformer
FunASR
大语言模型
★Qwen3.5
★Qwen3-VL
★MiniCPM-V-4
…等更多

YOLOv5s — 不同精度 bmodel 的输出对比。
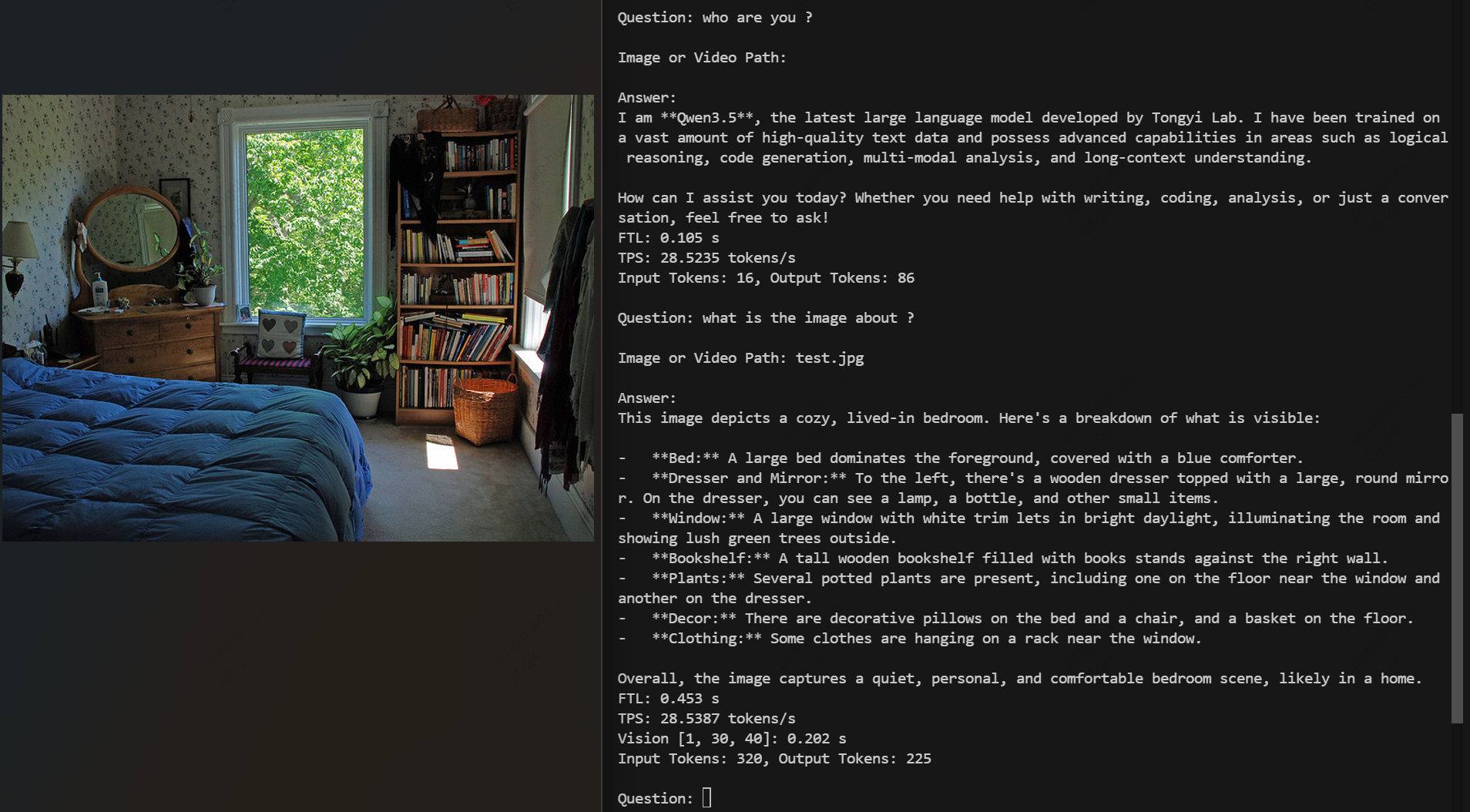
Qwen3.5-2B(INT4 / AutoRound)— 通过
llm_convert.py 编译后在算能 BM1684X 上运行对话。