DragGAN 概述#
DragGAN 来自于 SIGGraph 2023 接收的论文《Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold》。该模型可以以一张原始图片和用户交互(点)作为输入,在用户引导下修改图片:

DragGAN 的全流程包含一个基于 Generator 的前向操作和反向传播过程。本文主要介绍对 Generator模型部分前向操作的适配的全部过程。
模型移植#
推理代码定位与模型导出#
适配的模型代码使用 XingangPan/DragGAN: Official Code for DragGAN (SIGGRAPH 2023) (github.com) ,模型的入口在 DragGAN/viz/renderer.py:357,可以在这里直接引入 tpu-mlir 提供的 gen_shell 工具,直接 trace 生成 workspace 文件夹,onnx/pt 模型,以及默认的转换脚本:
1 | from utils.gen_shell import generate |
运行源码 README.md 中提供的脚本 python visualizer_drag_gradio.py,运行成功后可以在在同级目录下得到如下的目录结构:
1 | draggan_workspace |
模型移植过程中错误的分析和解决#
RuntimeError: Op not support:{‘RandomNormalLike’}#
在 model_transform 阶段,发现存在不支持的算子 RandomNormalLike:

RandomNormalLike(随机数相关)的算子 1684x 无法支持,所以必须尝试在原模型中避开这些算子。定位到模型代码处,发现该算子用于提供一个噪音供下游使用。源码中提供了三种噪音生成方式,分别是 random(随机噪音),const(常量噪音),和 none(不提供噪音),因此可以通过设置 noise_mode = const 避开这一算子的使用。

对 Conv/DeConv Filter 为动态输入情况的支持#
DragGan 的模型结构中,有一部分 Conv 和 DeConv 的输入是固定权重,而 FilterOp 部份是动态的从上游计算得到的输入。这种情况在这之前未做考虑,需要添加支持。这包括在多个地方的代码更改。下面通过具体的报错提示来一步步分析、定位和解决。
model_transform 阶段#
在 tpu-mlir 的 Converter 中,权重(weight)和 动态输入(dynamic input)存储在不同的变量中,其中,weight 通过 getWeightOp(name) 获取,input 通过 getOperand(name) 获取。如果不确定 op 是 dynamic input 还是 weight,可以使用 getOp(name) 来获取。而在对 DragGan 的 model_transform.py 脚本的运行过程中,会遇到如下的报错 KeyError: '/synthesis/b8/conv0/Transpose_output_0'
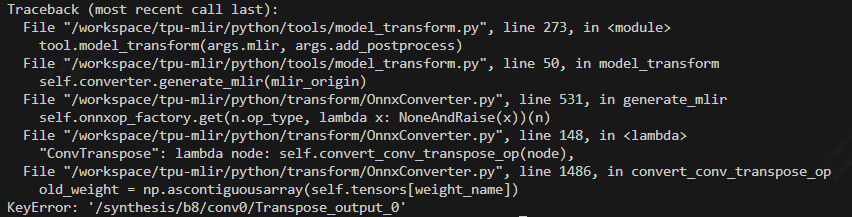
此时对应模型结构,发现该 DeConv 的输入 /synthesis/b8/conv0/Transpose_output_0 是作为一个 Weight 获取的。
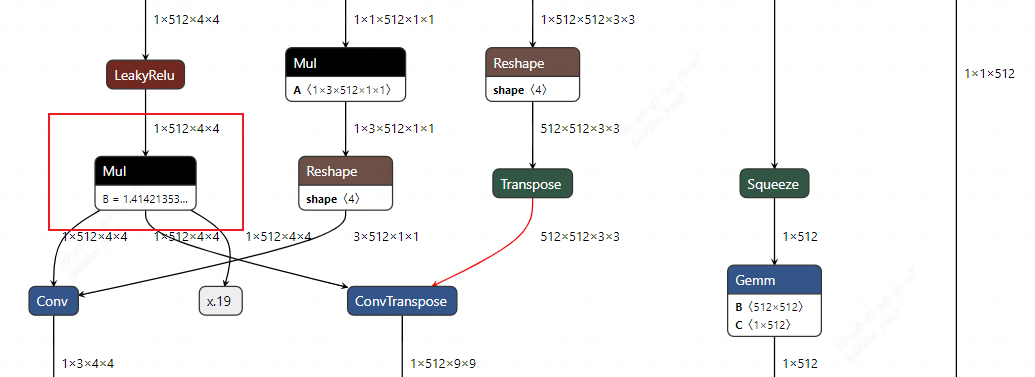
因此将ConvTranspose 的 filter_opd 的获取逻辑改为 getOp 即可

同理,另外一个 KeyError 中,DeConv 的 filter 来自于动态输入,所以同理,将 DeConv 获取 filter 结点的逻辑同样改为 getOp。

在 model_transform 阶段, 模型会首先转换到 DragGAN_origin.mlir,再经过 --shape-infer,--canonicalize 等过程,转换为可以通过 model_runner.py 做推理的 Top Dialect 描述的 mlir 文件。在对 Top 层做推理验证正确性时,DragGan 模型报出了精度为零的错误。通过观察输出的错误信息,发现是在 DeConv 层之后精度出现问题的,而且仅在 DeConv 的 filter 是动态输入的情况下会有这一问题。
构建了一个 filter 是动态输入的 DeConv 作为单侧,复现该错误成功:
1 | class DeConvCase(nn.Module): |
此时通过断点调试,发现错误原因有两个:
- 正确性验证阶段推理时,在
init()时设置权重,此时 weight 还没有设置 - 动态输入时没有做对应的权重重排(WeightReorder)
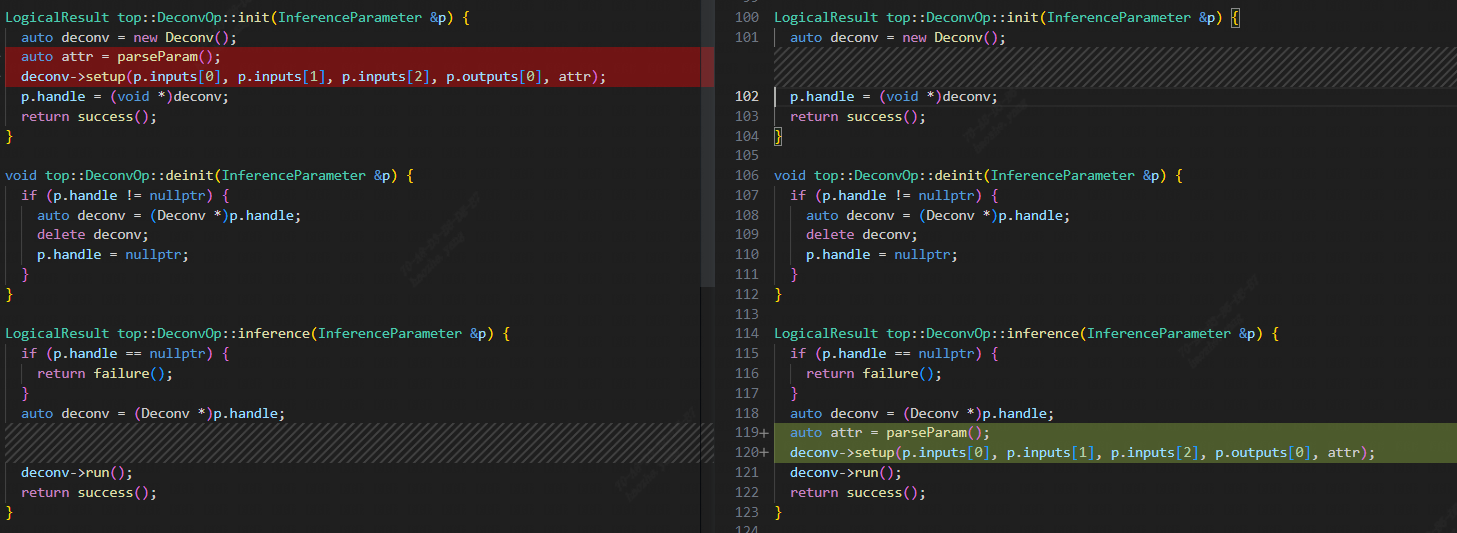
tpu-mlir 在适配模型的过程会经过多步转换和多次优化,为了保证转换后的正确性,tpu-mlir 会做三次正确性验证,分别针对 Top Dialect,Tpu Dialect 和 bmodel。Top 和 Tpu 层的正确性的核心代码位于 ModuleInterpreter.[h/cpp],该过程会从输入开始,对每一个 Op 分配空间,进行初始化(init),在初始化结束后进行推理(inference),并在最终对每个 Op 进行析构(deinit)。而 DeConv 的精度错误之一则来自于 Inference 阶段时 init 和 inference 的分离。
在 init 时,DeConv 会构造一个 Dnnl 的实例,此时会直接 copy 一份 Weight 在 Dnnl 实例中,但由于该 filter 为动态输入, init 时值还没有传入,所以传入的 filter 的值实质上是全零。导致在 inference 阶段出现错误。定位后该问题比较好改,将 init 过程中对 Dnnl 实例的 setup 移到 inference 阶段即可。Conv 也有同样的问题,修改逻辑相同。
对 onnx 模型,DeConv 的 filter 的权重存储方式是 input channel first(即 shape 为 [ic, oc, kw, kh]),而后端的计算过程大多都需要 output channel first([oc, ic, kw, kh]),可以注意到 OnnxConverter 中,原本对 DeConv 的权重会存在一个转置操作:
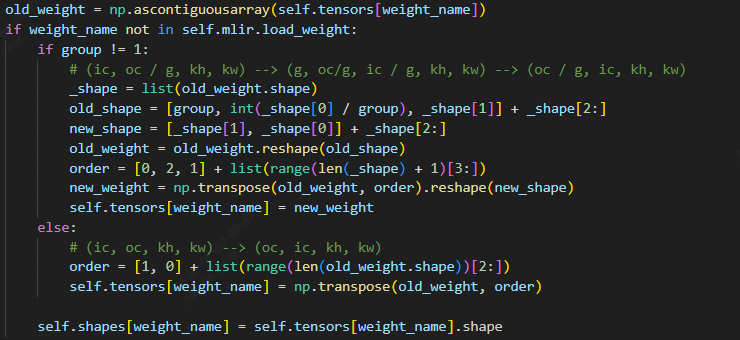
而动态权重自然没有办法实现这一操作。因此,需要添加一个图优化,当 DeConv 的 filter 是动态时,在其前面添加一个 [oc, ic] 互换的 Permute 操作。在添加 Permute 操作时,需要仔细考虑 DeConv 添加这一 Permute 的先决条件。确保该 Permute 添加是针对 DeConv 的动态权重,且同时不会重复添加。因此考虑在 DeConv 的 Operation 结构中添加 bool 类型的 dynweight_reorderd 参数。当 filter 不是 top.WeightOp (使用动态权重)且 dynweight_reordered 为 false (没有添加对动态 weight 的 Permute)时,添加这一 Permute,同时设置 dynweight_reorderd 参数为 true。
在 TopOps.td 文件对 DeConv 添加 dynweight_reorderd 参数后,对 DeConv 动态权重的图优化逻辑如下:
1 | struct ReorderDynWeight : public OpRewritePattern<DeconvOp> { |
这里做了一个额外的判断,当 DeConv 的 filter 位置已经是 Permute 且其 order 和要添加的 Permute 一样(1,0,2,3)时,两个 Permute 可以直接融合,所以此时可以直接删除该 Permute 并返回。其他的情况则是插入一个额外的 Permute 操作。Conv 层同样要支持动态 weight 的权重重排,要添加一个相同的图优化。
此外,Top 层的 shape-infer 要早于图优化,因此在做 shape-infer 时动态 weight 的 shape 仍然还是 input channle first,所以 DeConv 的 output_shape 的 dim[1] 应该基于 filter_shape[1] 来判断。对应的修改位于 lib/Dialect/Top/Interfaces/Deconv.cpp:

bmodel 运行错误 ASSERT /workspace/nntoolchain/TPU1686/bm1684x/cmodel/src/cmodel_common.cpp: gather_data: 207: dst_offset < (1<<18)#
在大模型中定位这一错误较难,因此可以通过 mlir_cut.py 逐步缩小范围,得到了最小可复现的 mlir:

1 | mlir_cut.py --mlir *tpu.mlir --output_names /synthesis/b64/conv0/Conv_output_0_Conv --input_names /synthesis/b32/conv1/Mul_3_output_0_Mul,/synthesis/b64/conv0/Reshape_3_output_0_Reshape |
进一步构建了能够复现该错误的单元测试:
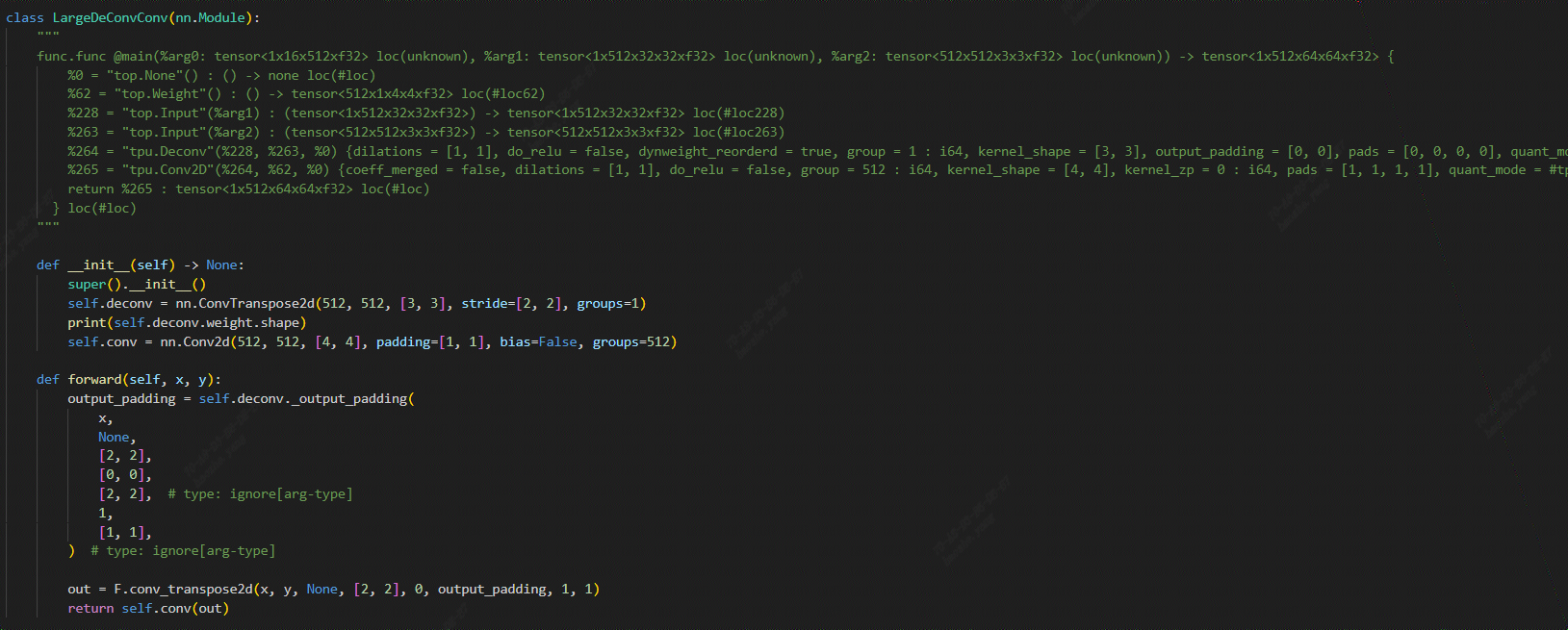
通过控制变量,得到了以下现象:
- 关闭
layer-group,模型运行正常不报错:这说明问题基本是出在 tpu-mlir 部份而不是后端算子部份 - 将上述的代码中 DeConv 的 filter 从动态改为静态,模型运行正常:说明问题仍然是动态 Weight 导致的
- 构建基本的 DeConv 算子,无论是静态和动态都运行正常,和上面的单侧进行对比,发现区别在单个 DeConv 算子不会进行 LayerGroup:将问题定位到 tpu-mlir 的 LayerGroup 部份的代码
此时进一步对比正常和出错的 final.mlir,发现 dynamic weight 和 weight 的 slice 属性不一致,如下所示:
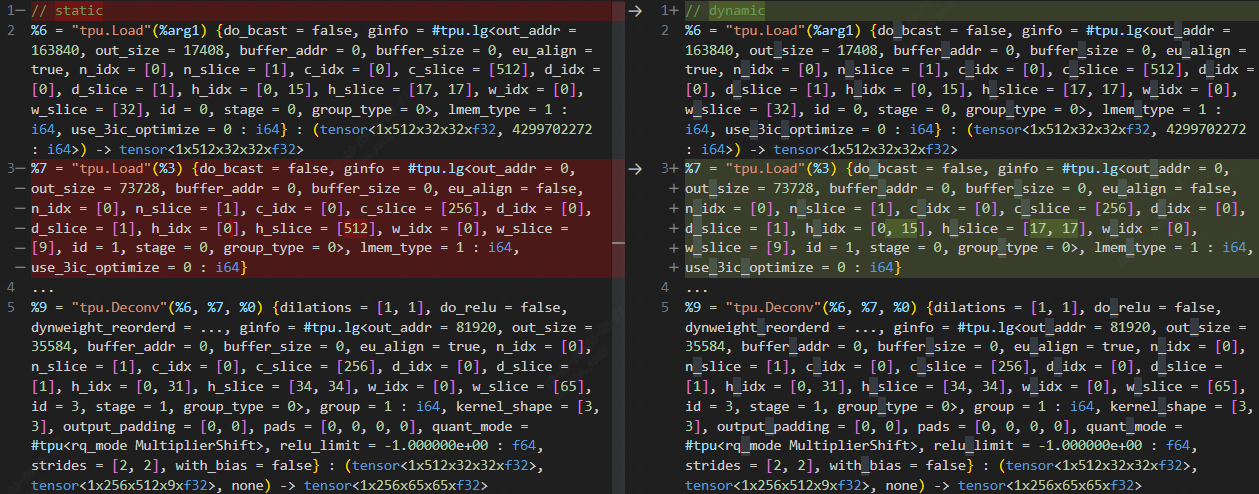
top.Weight 的 layer-group 是比较特殊。top.Weight 在整个 layer-group 都保存在 local memory 中(hold_in_lmem = true);同时,weight 也不能切分 slice,每个 slice 都要用到完成的 filter,从而导致结果错误。
所以需要单独针对 dynamic weight 处理,这包括设置其生命周期(hold_in_mem = true),以及将其 slice 设置为长度为 1,元素为其 shape 对应维度值的列表。这一过程可以在 lib/Dialect/Tpu/Transforms/LayerGroup/LayerGroupUtil.cpp 的 backward_update_slice 方法中完成:

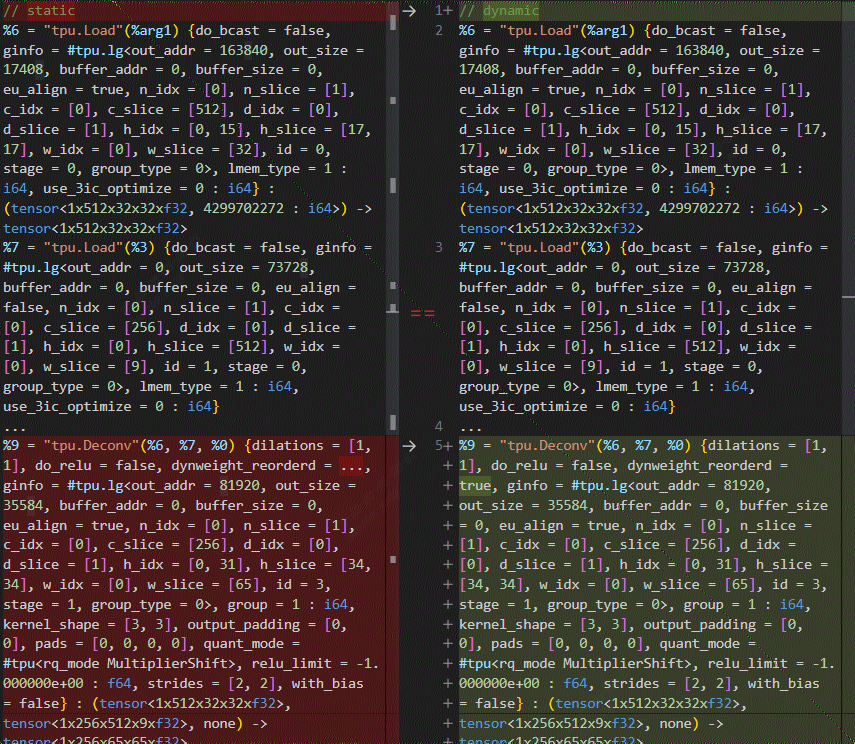
优化后再对比两个单例的 final.mlir,发现此时 dynamic weight 的 slice 信息已经和普通 weight 完全相同:
F16 和 int8 精度问题#
在解决了 F32 的 bug 后,F16 和 int8 的 tpu 层 mlir 仍然存在精度问题。原本以为是 DeConv 的 F16 适配存在问题,通过使用 mlir_debugger 对每一层用正确数值做推理(也可以直接观察输出的 npz 文件以及 npz_tool 的比对结果),发现出错的是 Active -> Mul 的结构,Active 是 ReduceSum 操作:
因此基本可以确定是普通的 F16 溢出问题。验证 BF16,发现BF16 编译成功,进一步确认是溢出问题。
将这些层添加到 qtable 中,发现还是通过不了比对,值里面仍然会存在 inf。对比发现是在 Active(ReduceSum) -> Sqrt 的结构中间有两个 Cast 导致的:

这两个 cast 没有作用,可以被优化掉,于是写图优化将这两个 Cast 直接消除。优化后对应的 mlir 如下:

int8 也是相同的精度溢出问题,同样确认两个 cast 融合的操作能够覆盖 int8 的情况即可。
至此,DragGan 适配的模型部份适配完成。
总结#
- 在一些情况下,在不影响结果的情况下直接修改模型的代码结构可以更容易的解决一些算子适配问题
- 较大的模型测试错误定位到具体算子的情况下,优先考虑构建单侧尝试复现问题
- 控制变量,设置对照,是缺少解决思路时寻找问题的一个较为通用的方案。