1. TPU软件与硬件架构#
完整的TPU推理应用是通过软硬件相互配合完成的,如下图所示:
软件方面,Host端实现了libsophon、驱动两个软件包。驱动负责对实际的Host与设备基础通信和资源管理机制的抽象,提供了基础的功能接口。对于TPU推理来说,libsophon提供了具体的功能,其中BMLib(libbmlib.so)实现对驱动接口封装,提供兼容保证,简化调用流程,提升编程的效率和可移植性,TPU-RUNTIME(libbmrt.so)提供了模型(bmodel)的加载、管理与执行等功能。
硬件方面,TPU内部主要由MCU、GDMA、TIU三个engine来完成工作的。
MCU在BM1684X上是一个单核的A53处理器,通过firmware固件程序完成向GDMA、TIU两个engine下发命令、驱动通信、简单计算等具体功能,实现了算子的具体逻辑。
GDMA和TIU是实际的执行引擎,GDMA用于Global mem与Local mem之间传输数据,实现了1D、矩阵、4D等数据搬运功能;TIU对local mem中的数据执行密集计算命令,包括卷积、矩阵乘法、算术等原子操作。

TPU Profile是将Profile数据转换为可视化网页的工具。Profile数据的来源包括内部GDMA PMU和TIU PMU两个硬件模块记录的运行计时数据、各个软件模块关键函数信息、bmodel里的元数据等。这些数据是在编译模型、以及应用运行时收集的。在实际部署中,默认是关闭的,可以通过环境变量来开启。
本文主要是利用Profile数据及TPU Profile工具,可视化模型的完整运行流程,来让读者对TPU内部有一个直观的认识。
2. 编译bmodel#
(本操作及下面操作会用到TPU-MLIR)
由于Profile数据会编译中的一些layer信息保存到bmodel中,导致bmodel体积变大,所以默认是关闭的。打开方式是在调用model_deploy.py加上--debug选项。如果在编译时未开启该选项,运行时开启Profile得到的数据在可视化时,会有部分数据缺失。
下面以tpu-mlir工程中的yolov5s模型来演示。
1 | 生成 top mlir |
通过以上命令,将yolov5s.onnx编译成了yolov5s_bm1684x_f16.bmodel。更多用法可以参见 TPU-MLIR
3. 生成Profile原始数据#
同编译过程,运行时的Profile功能默认是关闭的,防止在做profile保存与传输时产生额外时间消耗。需要开启profile功能时,在运行编译好的应用前设置环境变量BMRUNTIME_ENABLE_PROFILE=1即可。
下面用libsophon中提供的模型测试工具bmrt_test来作为应用,生成profile数据。
1 | 通过环境变量(BMRUNTIME_ENABLE_PROFILE)使能profile, 生成二进制数据 |
下面是开启Profile后运行输出的日志
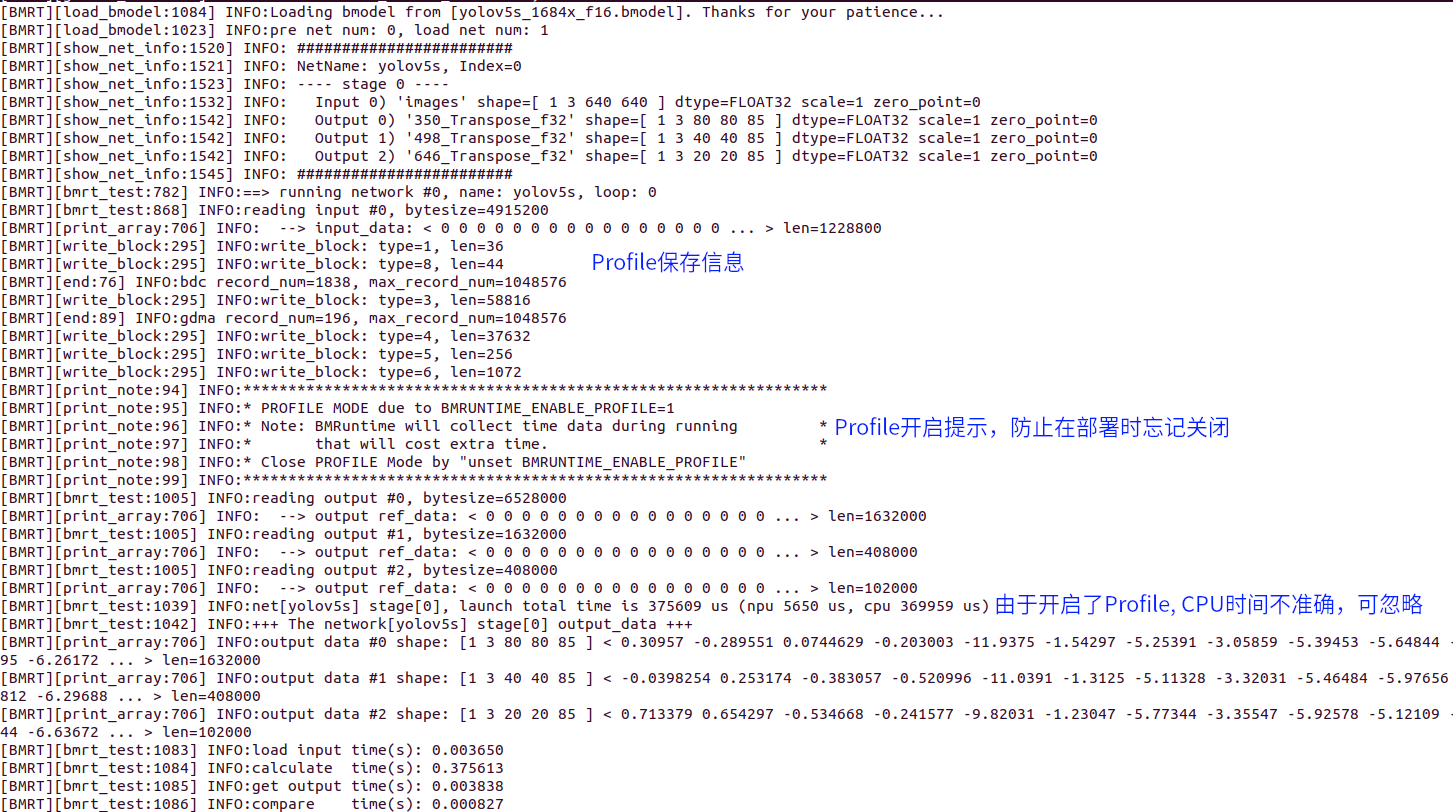
同时在当前目录生成bmprofile_data-1文件夹, 为全部的Profile数据。
4. 可视化Profile数据#
tpu-mlir提供了tpu_profile.py脚本,来把生成的二进制profile数据转换成网页文件,来进行可视化。
命令如下:
1 | 将bmprofile_data_0目录的profile原始数据转换成网页放置到bmprofile_out目录 |
用浏览器打开bmprofile_out/result.html可以看到profile的图表
此外,该工具还有其他用法,可以通过tpu_profile.py --help来查看。
5. 结果分析#
5.1 整体界面说明#
完整界面大致可分为运行时序图和内存时空图。默认情况下内存时空图是折叠的,需要通过界面的“显示LOCALMEM”和“显示GLOBAL MEM”来展开。
下面对这两部分分别说明如何来分析TPU运行状态
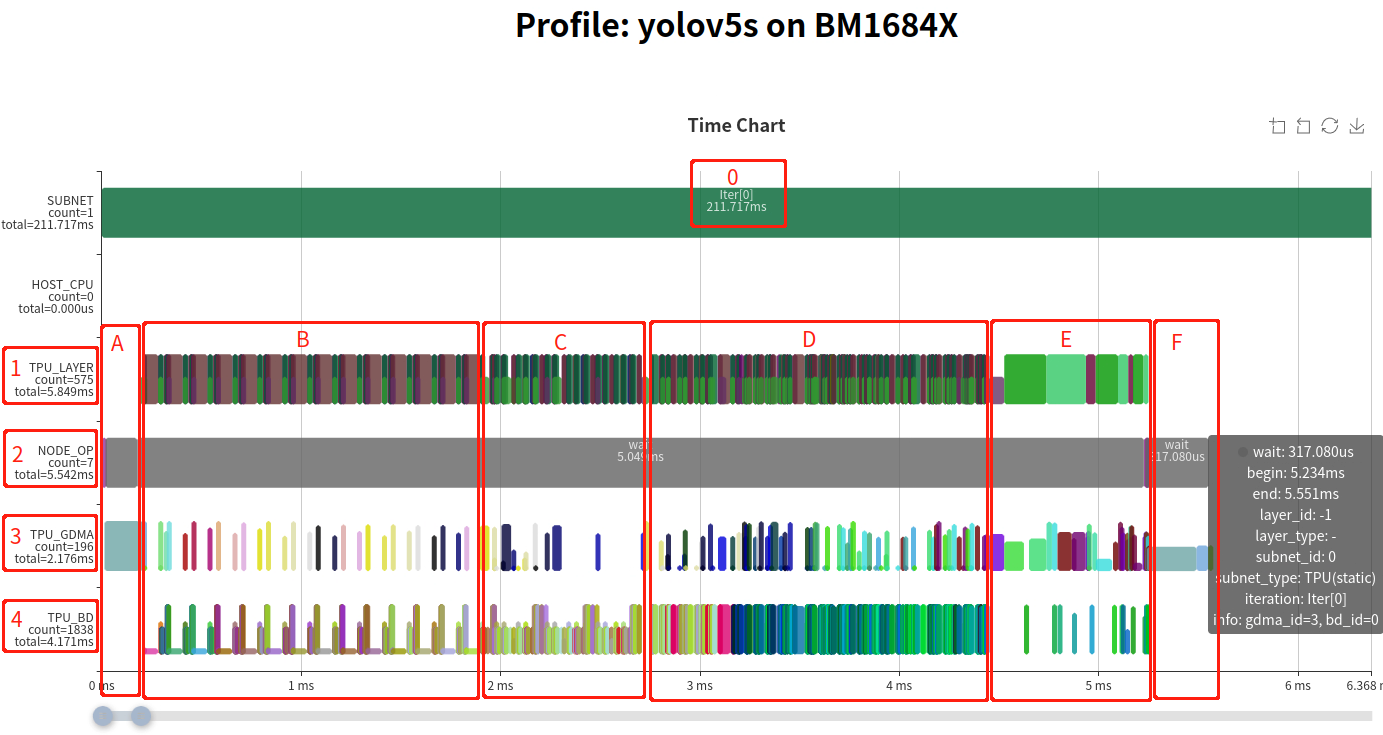
上图是运行时序图,根据图中标号说明如下
- 在做Profile时,在Host的时间可能不准确,该部分仅用于表示子网分隔标记。
- 该行表示的是整个网络中各个Layer的时序,是由下面的TPU_GDMA, TPU_BD(TIU)实际运行衍生计算得来。一个Layer Group会将一段算子分成数据搬运和计算两部分,并且是并行运行的,所以用半高的色块表示数据搬运,全高表示计算,避免重叠。
- 该行表示MCU上的操作,记录的关键函数包括设置GDMA、TIU指令及等待完成等。加和后通常可以表示完整的实际j运行时间。
- 该行表示TPU中GDMA操作的时序。其中色块的高度表示实际使用的数据传输带宽大小。
- 该行表示TPU中TIU操作的的时序。其中色块高度表示该计算的有效利用率。
从NODE_OP的下方的统计total=5.542ms,说明整个网络运行时间是5.542ms, 也可以看出在实际网络运行时,配置指令只占非常短的时间,大部时间在等待。
整体运行过程可以分为三个部分A段, B-E段, F段。其中,A段是利用MCU将用户空间的输入数据搬运到计算指令空间;F段是利用MCU将计算指令空间的输出数据搬回到用户空间。下面主要对B-E段的模型计算过程进行说明。
熟悉TPU-MLIR的同学应该清楚,完整的网络并不是Layer By Layer来运行的,中间会经过将多个Layer根据硬件资源和调度关系进行融合,将加载、计算、保存分离出来,去掉中间不必要的数据搬进与搬出,形成一个Layer Group,并划分成多个Slice来周期运行。整个网络根据结构可能会分成多个Layer Group。可以观察B、C、D段的Layer Pattern,中间有半高的加载保存操作,而且呈现了一定周期的循环,根据这些,我们可以判断出B、C、D是三个被融合后的Layer Group。而且后面E段并没有明显的周期,这几个Layer是没有被融合的Global Layer。
整体上看,网络中只有20%的部分没有被融合,在这个层面上看,网络结构对于编译器相对比较友好。
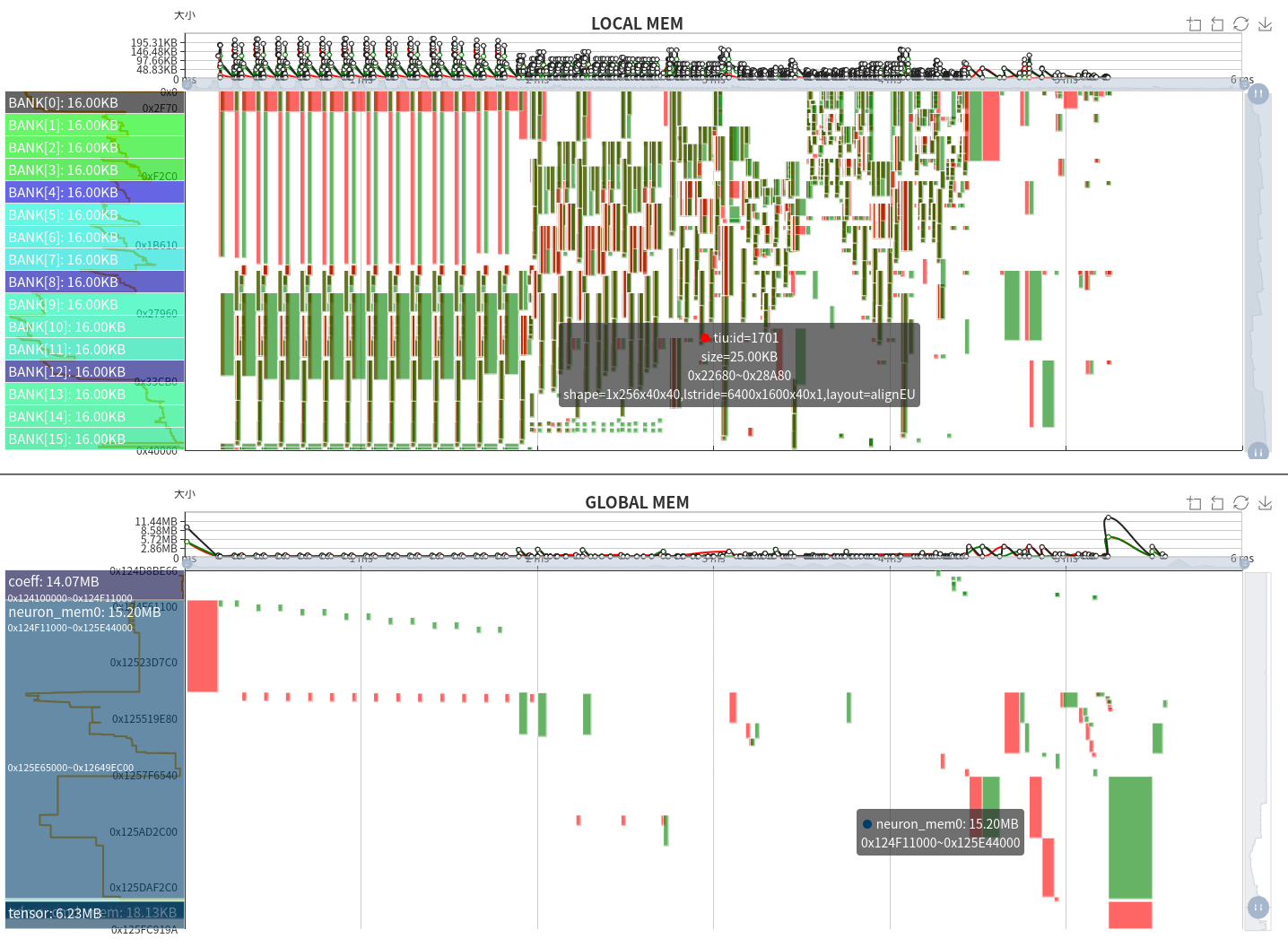
上图是整体的内存时空图,包括了LOCAL MEM和GLOBAL MEM上下两部分。横轴表示时间,可以结合上面的运行时序图来看。纵轴表示内存空间范围。图中绿色块高度表示占用空间大小,宽度表示占用时间长短,此外,红色表示GDMA写入或TIU输出,绿色表示GDMA读取或TIU输入。
LOCAL MEM是TPU内部计算空间,对于BM1684X来说,TIU一共有64个Lane,每个Lane可使用128KB的内存,并分为了16个bank。由于各个Lane的操作与内存是一致的,故图中只放了Lane0的内存占用情况。在计算过程中,还有一个需要注意的地方,计算的输入和输出最好不要在同一个Bank上,由于数据读写冲突,会影响计算效率。
GLOBAL MEM空间相对比较庞大,通常在4GB-12GB范围,为方便显示,只针对运行时使用的空间块进行显示。由于只有GDMA能与GLOBAL MEM通信,故绿色表示GDMA的读取操作,红色表示GDMA的写入操作。
从内存时空图中可以看出,对于Layer Group来说,Local Mem的使用也呈周期性;TIU的输入和输出通常是在每个Bank边界上,并且没有冲突。仅就这个网络来说,Local Mem占用空间相对均匀,整个范围都有分布。从GLOBAL MEM的时空图上可以看到,以Layer Group运行时,写数据操作相对较少,读数据偏多。而在Global Layer运行时,会经过写回->读出->写回->…等操作。
此外,还可以看到运行时的GLOBAL MEM空间占用细节,可以分解为Coeff占用14.07MB, Runtime占用15.20MB, Tensor占用6.23MB。
5.2 Global Layer#
下面以比较简单的Global Layer来分析,根据Layer信息,Cast的前一层由于是Permute(图中未显示)导致无法与其他算子融合。
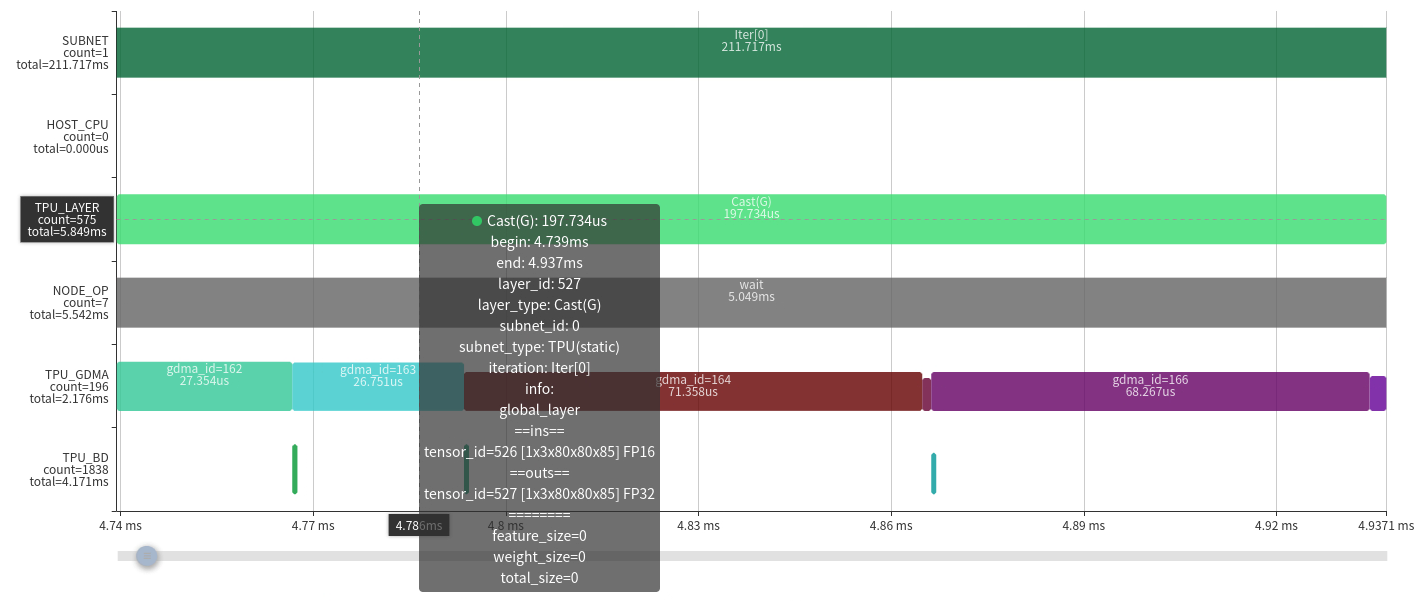

从Layer上可以看到参数信息,当前层是将1x3x80x80x85的fp16 tensor数据转换为fp32。
计算过程为
1 | time ---------------------------------------> |
由于只有一个GDMA器件,Load和Store只能串行执行,所以流水变成了
1 | time ---------------------------------------> |
从对应的内存时空图也可以看出完整的数据流动关系,输入数据是fp16转换到输出fp32后,内存翻倍了,因而传输时间大概为原来的两倍。
在计算过程中虽然已经做到流水并行,但由于受带宽限制,无法满足算力的需要,所以整个运行时间取决于数据搬进与搬出的时间。从另一方面也说明了Layer融合的必要性。
5.3 Local Layer Group#
根据上面的Layer Group的情况,分为两种case来分析:
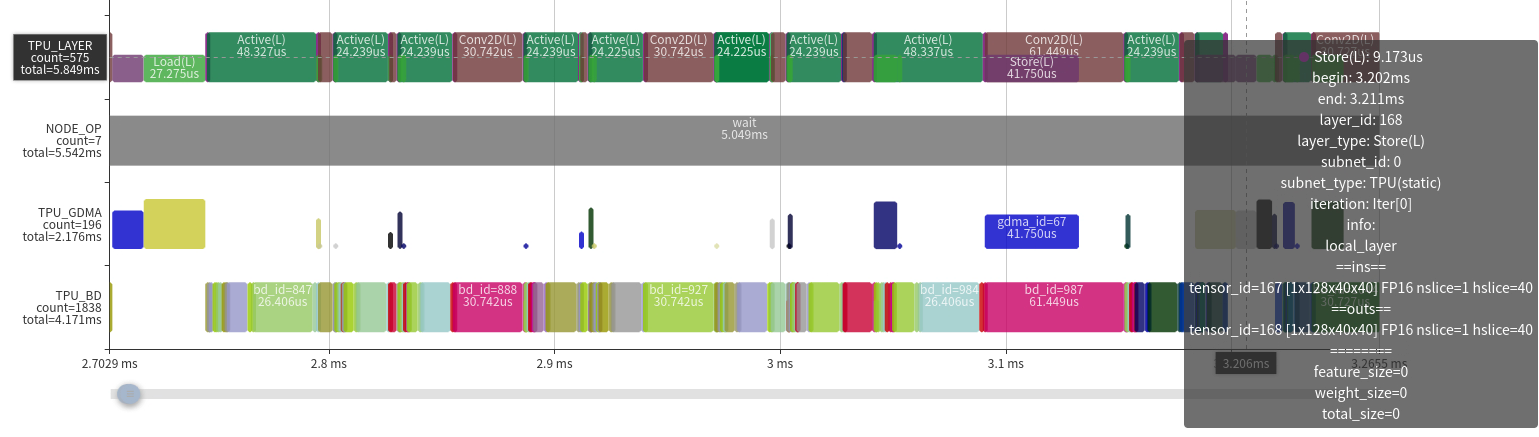
- 效率较高的情况。主要特征是
- 除了前面和后面,中间的只有很少的GDMA操作,显著地减少了数据的搬进搬出。
- TIU操作效率都比较高,几乎是算力全部是有效的
- TIU操作之间没有空隙(也是因为GDMA传输时间比较短)
在这种情况下,可提升的空间非常有限了,只能从网络结构或其他方面来优化。

- 算力利用率比较低的情况。这种情况主要是网络算子参数与我们TPU的架构不友好造成的。我们的BM1684X上有64个Lane,对应于输入的IC,也就是说输入IC是64倍数才能充分利用TIU的Conv原子操作。但从图中参数可以看到网络Conv的输入Channel为3,导致有效计算只有3/64。
遇到参数不友好的情况,有以下种解决办法:
- 充分利用LOCAL MEM增大Slice以减少循环次数;
- 利用一些变换,如数据排列,来充分利用TPU。其实对于首层为输入Channel为3的情况,我们引入了一种3IC的技术,已经解决了这种计算效率低的问题;
- 修改原始代码,调整相关计算。
在实际中,也遇到过很多无法避免的效率低下的情况,只能随着我们对TPU计算理解逐步加深,通过改进TPU架构或指令来解决。
6. 总结#
本文演示了对TPU做Profile的完整流程,并介绍了如何利用Profile的可视化图表来分析TPU中的运行过程与问题。
Profile工具对我们开发AI编译器来说,是一个必要的工具。我们不仅需要在理论上分析和思考优化手段和方法,还需要从处理器内部实际运行角度来观察计算过程中的瓶颈,可以软件和硬件设计和演进提供深层次的信息。另外,Profile工具也为我们Debug提供了一种手段,可以我们直观地发现错误,比如内存踩踏、同步出错等问题。
此外,TPU Profile的显示功能在不断完善中,欢迎大家提供宝贵意见。