AI 模型训练好之后最终还是要投入生产环境,这时候就会发现编译器几乎是绕不开的话题,尤其是在边缘设备部署 AI 模型时,模型能否发挥优势还要取决于它所运行的硬件,了解模型在不同硬件加速器上的编译和优化变得非常重要。
理想情况下,编译器无需算法工程师来操心,但是现在的编译器远没有那么智能。随着 AI 应用在边缘的落地,AI 编译器的开发也越来越多,以弥补 AI 模型和算力硬件之间的差距-MLIR ,TVM,XLA,PyTorch Glow,cuDNN 等。
PyTorch 创始人 Soumith Chintala 认为,随着深度学习的成熟应用,大公司之间的竞争将会变为编译器的竞争,了解编译原理可以帮助工程师选择正确的编译器,将模型高效部署到硬件上,并诊断性能问题,提高模型的速度。
边缘计算将编译器从系统工程师的领域带入了普通 AI 应用者的领域,下面分几个部分对编译器相关的技术和生态做一个系统的介绍。
1. 边缘计算和云计算#
想象一下,算法工程师训练了一个令人难以置信的 AI 模型,其准确性超出了预期,希望能够快速部署这个模型,让用户使用。
最简单的方法是将模型打包并传到 AWS 或 GCP 之类的托管云服务进行部署,这也是许多公司最开始部署模型的方式,云服务确实降低了部署的难度可以快速投产。
然而,云部署也有许多缺点。首先是成本。AI 模型可以是计算密集型的,而计算是昂贵的。早在 2018 年,像 Pinterest,Infor,Intuit 等大公司每年已经在云服务上的开销就达到了数亿美元,对于中小型企业而言,这个数字可能在每年 5 万至 200 万美元之间。
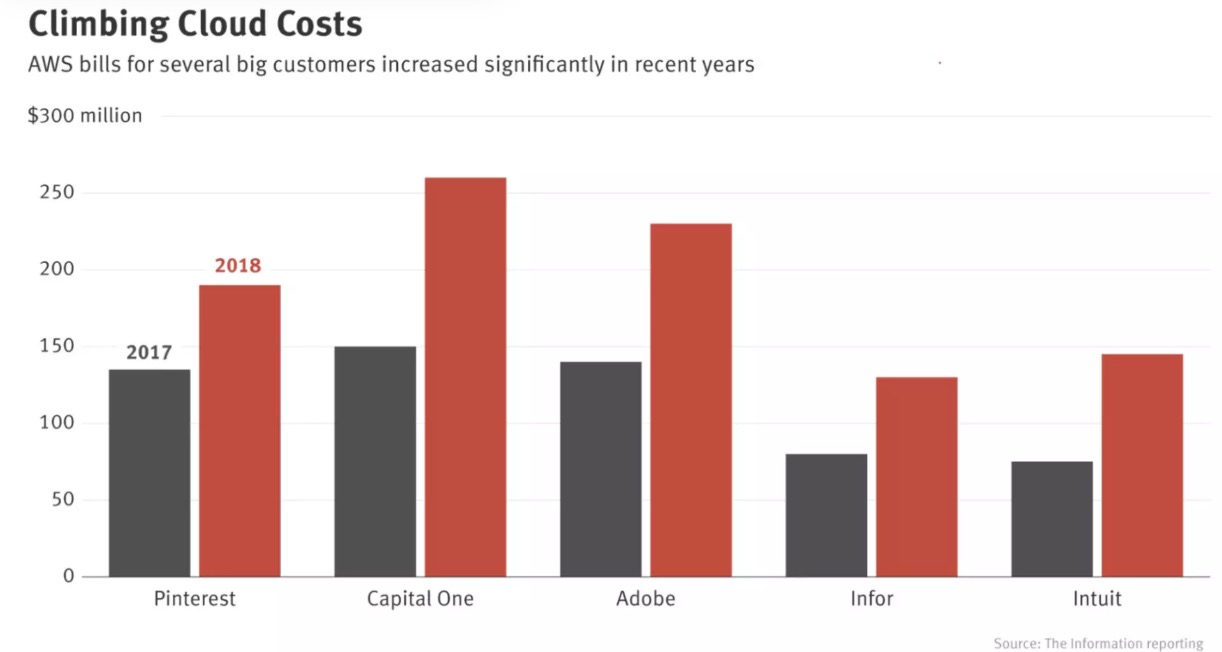
各大公司在 AWS 的账单
随着云计算费用的攀升,越来越多的公司开始寻找将计算推向消费设备(边缘设备)的方法,边缘计算完成得越多,云所需的计算量就越少,他们为服务器支付的费用也就越少。
除了有助于控制成本,边缘计算还有许多优点,首先,它允许应用程序在云计算无法运行的地方运行,当模型位于云上时,它们要依赖稳定的网络连接传输数据,边缘计算则允许模型在没有互联网连接或连接不可用的情况下工作。
其次,当模型已经部署在用户的设备上时,无需再担心网络延迟。很多时候,网络延迟会带来比推理延迟更大的瓶颈,比如云端 ResNet50 的推理延迟可以从 30ms 减少到 20ms,但是网络延迟可以高达几秒。
在处理敏感用户数据时,将模型置于边缘端也很有吸引力。云服务意味着系统不得不通过网络发送用户数据,而传输过程中数据很容易被拦截,而且许多用户的数据存储在同一个地方,一个漏洞可能会影响许多人,据《安全》杂志 2020 年的报道,近 80% 的公司在过去 18 个月出现过云数据泄露。
2. 编译: 解决兼容性问题#
由于边缘计算相对于云计算的诸多好处,各大公司都在竞相开发可以优化 AI 模型的边缘设备。包括谷歌(Google)、苹果(Apple)、特斯拉(Tesla)在内的老牌公司都宣布了自己造芯计划,与此同时,AI 处理器公司不断涌现。
有这么多新的算力硬件产品可以运行 AI 模型,一个问题出现了: 我们如何建立一个在任意硬件上都能运行任意框架的模型?
要在一个硬件上运行一个框架,它必须得到硬件供应商的支持,尽管 TPU 在 2018 年 2 月公开发布,但直到 2020 年 9 月才支持 PyTorch,在此之前,如果想使用 TPU,那么必须使用 TensorFlow 或 JAX,目前算能的 TPU 已经可以支持市面上大部分框架,算法移植非常方便,TPU 编译器工程 tpu-mlir 也已在 GitHub 上开源。
在一种类型的硬件(平台)上提供特定框架的支持是非常耗时的,从 AI 工作负载到硬件的映射需要理解并能够利用硬件的基础计算单元,然而,不同的硬件类型有不同的内存布局和计算原语。
CPU 的计算基元过去是一个数字(标量) ,GPU 的计算基元过去是一维向量,而 TPU 的计算基元是二维向量(张量)。现在很多 CPU 都有了矢量指令,一些 GPU 也有张量核,在 GPU 上对 256x 3 x 224 x 224 的数据进行卷积,与使用一维向量会有很大的不同,此外还需要考虑不同的 L1、 L2 和 L3 布局和缓冲区大小,以便更高效地使用各个计算单元。
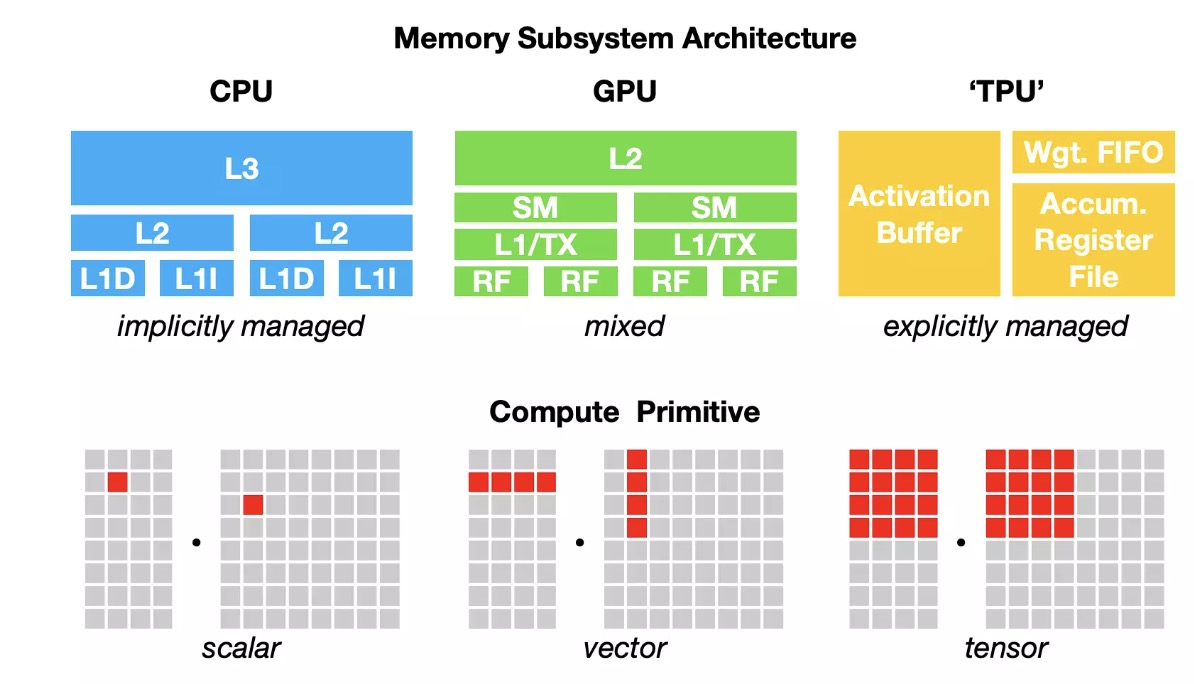
不同硬件后端的计算单元和内存布局
正因为如此,框架开发人员倾向于只为少数服务器级硬件(例如 GPU)提供支持,而硬件供应商倾向于为更少的框架提供自己的内核库(例如,英特尔的 OpenVino 只支持 Caffe、 TensorFlow、 MXNet、 Kaldi 和 ONNX,NVIDIA 拥有 CUDA 和 cuDNN)。将 AI 模型部署到新的硬件需要大量的工作量,例如嵌入式设备、 FPGA 和 ASIC 等。
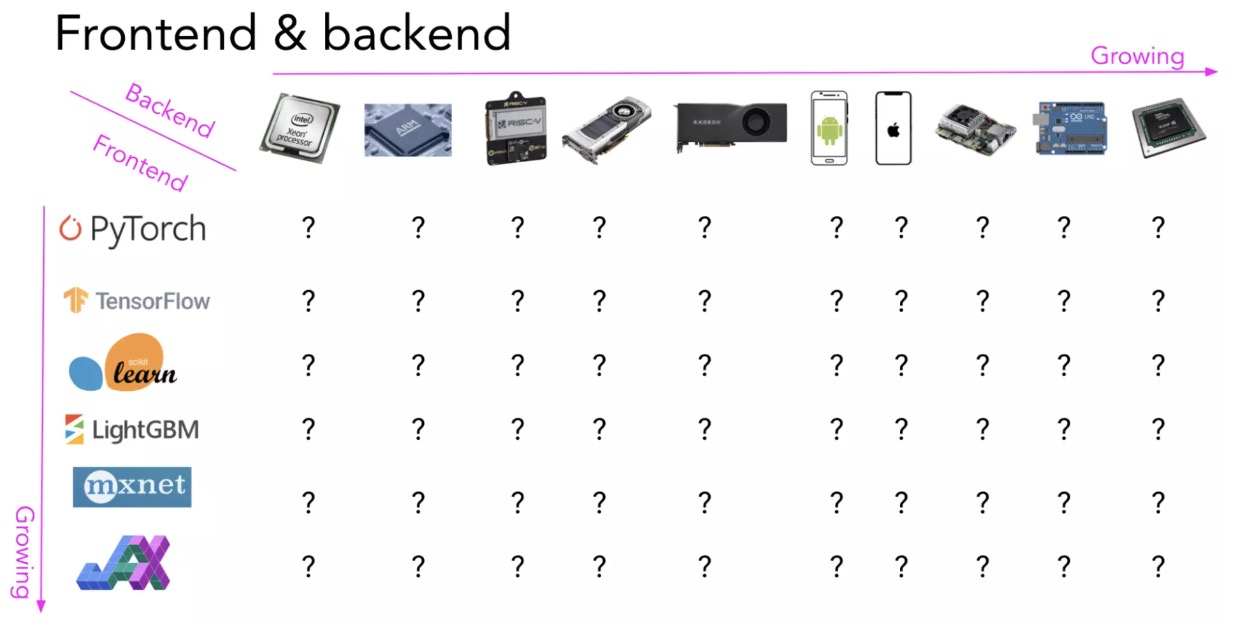
种类繁多的硬件形态和编程框架
中间表示(IR)
与其为每种新的硬件类型和设备制作新的编译器和库,不如创建一个中间人来连接框架和平台。框架开发人员不用支持所有类型的硬件,只需要将他们的框架代码转换成这个中间人,硬件供应商也支持这个中间人,就能解决这个问题。
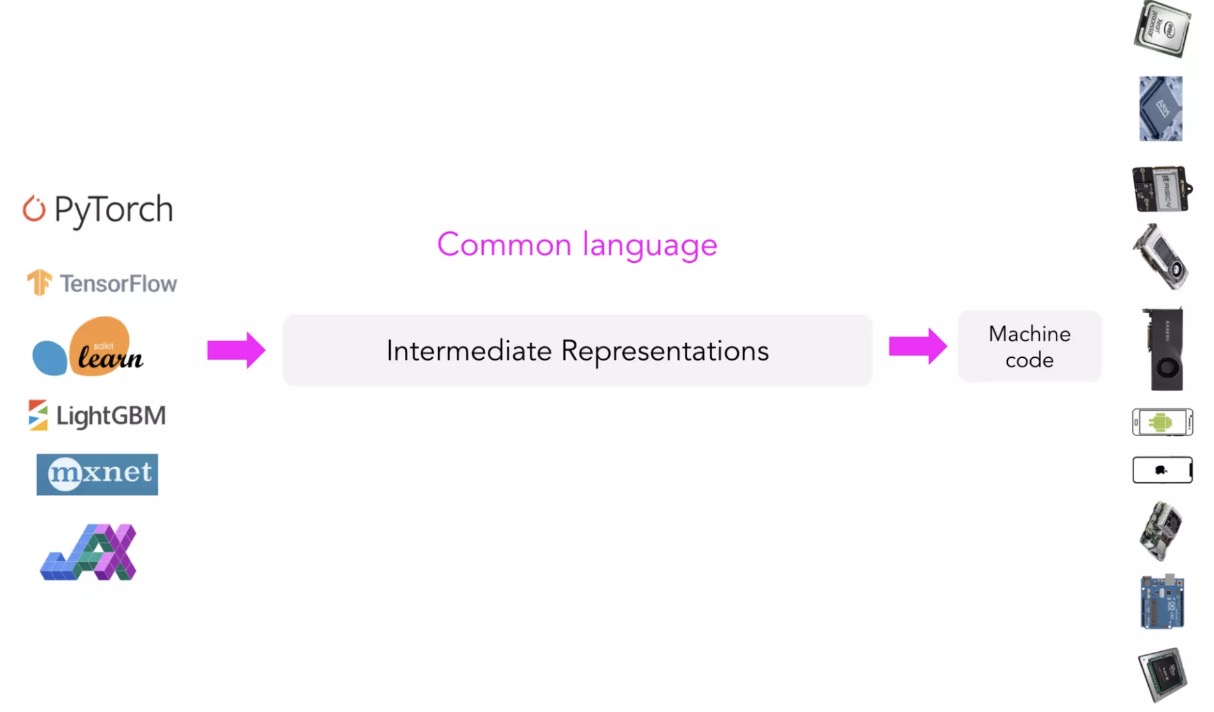
作为中间人的 IR
这种类型的“中间人”被称为中间表示(IR),IRs 是编译器工作的核心。从模型的原始代码开始,编译器生成一系列高级和低级的中间表示,然后生成硬件机器码,以便在某个平台上运行。
为了从 IR 生成机器代码,编译器通常利用 Codegen(代码生成器)来生成机器码,AI 编译器使用的最多的是 LLVM,由 Vikram Adve 和 Chris Lattner 开发(他们通过创建 LLVM 改变了我们对系统工程的概念)。TensorFlow XLA、 NVIDIA CUDA 编译器(NVCC)、 MLIR (用于构建其他编译器的元编译器)和 TVM 都使用 LLVM。
这个过程也称为“lowering”,就是将高级框架代码“降低”为低级硬件机器码,这不是“翻译”,因为它们之间没有一对一的映射。
高级 IR 通常是 ML 模型的计算图。对于熟悉 TensorFlow 的人来说,在 TensorFlow 切换到 eager execution 之前,这里的计算图类似于 TensorFlow 1.0 中遇到的计算图。在 TensorFlow 1.0 中,TensorFlow 在运行模型之前首先构建了模型的计算图,这个计算图允许 TensorFlow 理解模型并优化其运行时。
高级别的 IR 通常是与硬件无关的(不关心它在什么硬件上运行) ,而低级别的 IR 通常是与框架无关的(不关心模型是用什么框架构建的),那么如何优化 IR 呢?
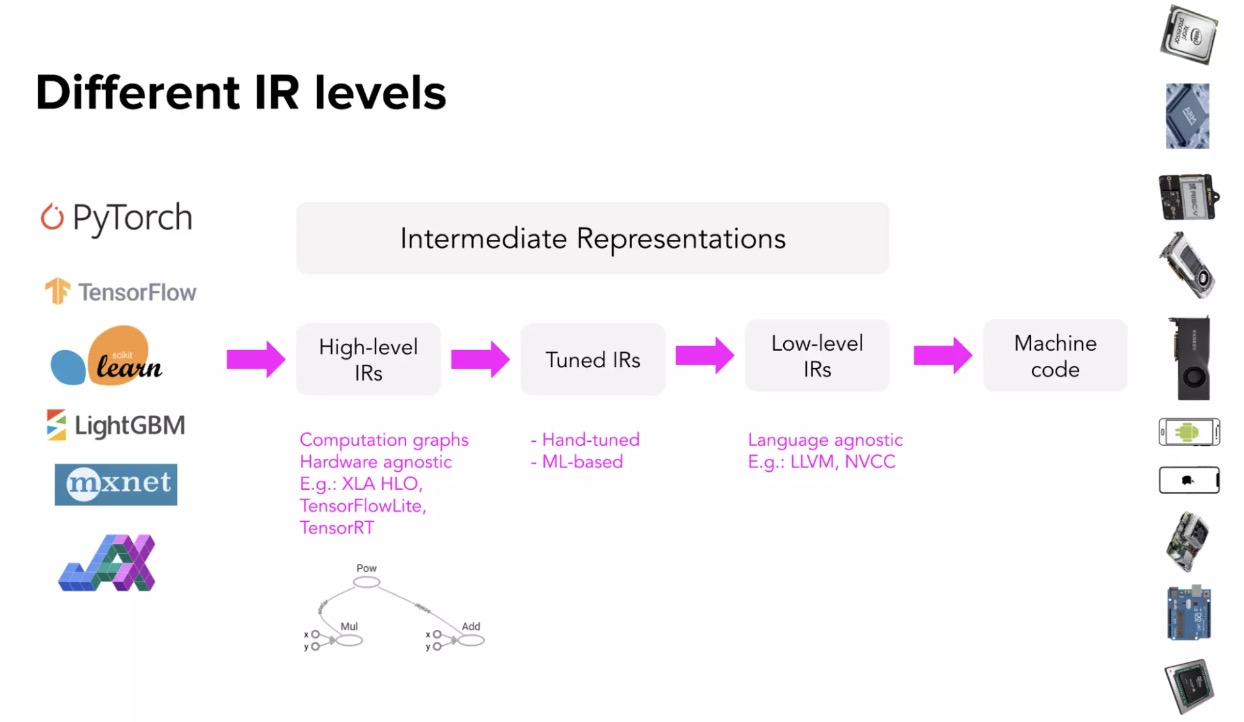
高级别和低级别 IR
3. 优化: 解决效率问题#
在“降低”代码以便将模型运行到所选硬件后,可能会遇到的一个问题是性能。Codegen 非常善于将 IR 降低到机器代码,但是根据目标硬件后端的不同,生成的机器代码可能不能执行得很好,生成的代码可能没有利用数据本地化和硬件缓存,也可能没有利用可以提高代码速度的向量或并行操作等高级特性。
典型的机器学习工作流由许多框架和库组成。例如,可以使用 Pandas/dask/ray 来处理数据,使用 NumPy 来执行向量化,使用 LightGBM 这样的树模型来生成特征,然后使用使用 sklearn、 TensorFlow 或 transformers 等构建的模型集合进行预测。
尽管这些框架中的单个函数可能被优化,但是跨框架的优化很少甚至没有。在这些函数之间移动数据进行计算的话,可能会导致整个 pipeline 呈数量级的降速。斯坦福 DAWN 实验室研究人员的一项研究发现,使用 NumPy、 Pandas 和 TensorFlow 的典型机器学习工作负载在一个线程中的运行速度比手工优化的代码慢 23 倍。
生产中经常发生的情况是,数据科学家/机器学习工程师为他们的工作安装所需的软件包,在开发环境中,一切运行良好,但模型部署到生产环境就开始出现性能问题,很多公司雇佣优化工程师来优化代码。
优化工程师聘用成本高昂,因为他们需要机器学习和硬件架构方面的专业知识,优化编译器(也可以优化代码的编译器)是另一种解决方案,因为它们可以自动化优化模型的过程。在将 AI 模型代码降低为机器代码的过程中,编译器可以查看模型的计算图和它所包含的运算符ーー卷积、循环、交叉熵ーー并找到加速它的方法。
总结一下就是编译器在 AI 模型和它们所运行的硬件之间架起了桥梁,编译器最优化由两部分组成: 降低 lowering 和优化 optimizing。
Lowering: 编译器为模型生成硬件机器码,让模型可以在特定硬件上运行
Optimizing: 优化模型在硬件上的运行效率
这两个部分不一定是分开的,优化可以发生在所有阶段,从高级别的 IRs 到低级别的 IRs,有了这些 IRs,模型就可以转换成可以在边缘设备高效运行的机器码。