有两种方法可以优化AI模型: 本地的和全局的。本地是优化模型的一个运算符或一组运算符,全局优化是指对整个计算图端到端进行优化。
AI模型优化利器:算子融合和循环拼接#
现在有一些标准的局部优化技术可以提高模型的速度,以下是四种常用的技术,其中大多数技术可以使计算并行或减少处理器上的内存访问。
- 向量化: 给定一个循环或嵌套循环,并且不是一次执行一个项目,而是使用硬件原语对内存中连续的多个元素进行操作。
- 并行化: 给定一个输入数组(或 n 维数组) ,将其划分为不同的、独立的工作块,并分别对每个工作块执行操作。
- 循环平铺: 改变循环中的数据访问顺序,以利用硬件的内存布局和缓存。这种优化依赖于硬件,在CPU 上高效, GPU 上不一定。
- 操作符融合: 将多个操作符融合为一个,以避免冗余内存访问。例如,同一数组上的两个操作需要该数组上的两个循环。融合之后只有一个循环,请看下面 Matthias Boehm 的一个例子。

循环拼接

算子融合
根据 Weld (另一个编译器)的创建者 Shoumik Palkar 的说法,这些标准的局部优化技术可望提高约3倍的速度。当然,这个估计是高度依赖上下文的。
为了获得更大的加速,需要利用计算图的高级结构。例如,给定一个具有计算图的卷积神经网络,可以纵向或横向融合,以减少内存访问和加速模型。 下图是NVIDIA 的 TensorRT 团队的例子。
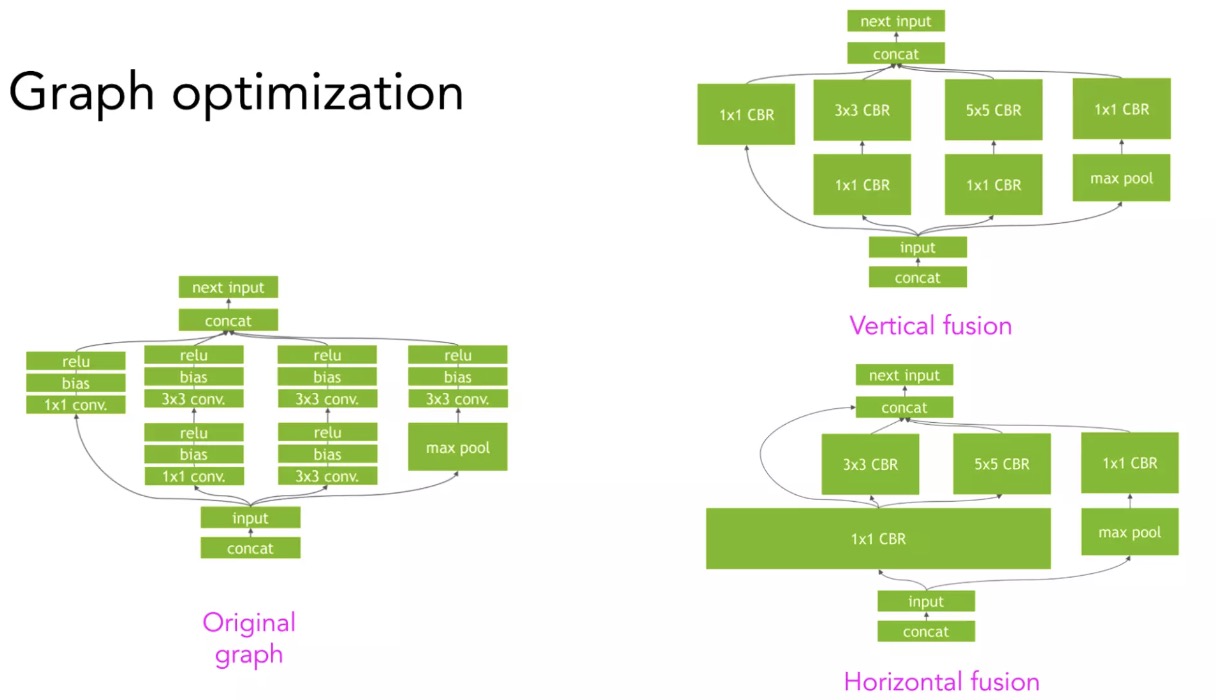
卷积神经网络计算图的纵向与横向融合
MLPerf跑分经过特殊优化,不能作为性能评估唯一标准#
正如前面关于卷积神经网络的纵向和横向融合的部分所讲的,有许多方法来执行给定的计算图。例如,给定3个操作符 A、 B 和 C,您可以将 A 与 B 融合,将 B 与 C 融合,或者将 A、 B 和 C 一起融合。
传统上,框架和硬件供应商会雇佣优化工程师,根据自己的经验,提出如何最好地执行模型计算图的启发式方法。例如,NVIDIA 可能有一个工程师或一个工程师团队,他们专门致力于优化 ResNet-50在 DGX A100服务器上的运行效率,这也是为什么我们不应该过度解读MLPerf 的结果。在某种类型的硬件上运行得非常快的流行模型并不意味着其他模型在该硬件上运行得非常快,可能只是因为这个模型被过度优化了。
手工设计的规则有几个缺点。首先,它们不是最优的,不能保证工程师提出的启发式方法是最好的解决方案。
其次,它们是非适应性的,在新框架或新硬件体系结构上重复这个过程需要大量的工作。
模型优化是依赖于构成其计算图的一组算子,优化卷积神经网络不同于优化递归神经网络,也不同于优化Transformer。NVIDIA 和谷歌专注于优化其硬件上的流行模型,如 ResNet 和 BERT。
但是,如果提出一个新的模型架构会怎样呢?可能需要自己对它进行优化,因为硬件供应商的优化要滞后很多。