TPU-MLIR 开源 AI 编译器的视频教程,已经同步更新 B 站、知乎、CSDN 等平台,旨在通过一系列的课程让观众一步步深入了解 AI 编译器的原理及开发。
视频分享主要基于算能的开源工具链 TPU-MLIR 展开,内容会涵盖 MLIR 基本语法以及编译器中各类优化操作的实现细节,如图优化,int8 量化,算子切分和地址分配等。
AI 编译器主要功能:简化网络搭建、提升网络性能#
计算机中的传统编译器,可以将各种高级语言例如 C++、Python 等编程语言转为统一的计算机可理解的低级语言,本质上 AI 编译器与传统编译器很相似,只不过要转换的对象变为了各种深度学习框架构建和训练出来的网络,也称之为计算图,而构建这一计算图的各个小的计算模块例如 relu 和 pooling 等,也称之为算子。
显然,通过高级语言可以更高效地编程,语言转换的工作直接交给编译器完成就行。传统编译器和 AI 编译器的主要区别是,前者的主要目的是为了降低编程难度,而 AI 编译器虽然也起到了简化网络搭建难度的作用,但最主要的功能是提升网络性能。

作为图形处理器的 GPU,在进行 AI 计算时有一定的限制,例如 GPU 的运行要依赖 CPU 的调用,而且基于现有的冯·诺依曼结构的经典计算机运行时,就不可避免地受到存储与计算分离的限制,从而影响整体的工作效率,
TPU 是专门用于人工智能算法的张量处理器,但想要 TPU 更高效发挥作用,就需要 AI 编译器这个中间桥梁,AI 编译器到底如何提升 TPU 的计算效率,敬请观看详细的视频课程。
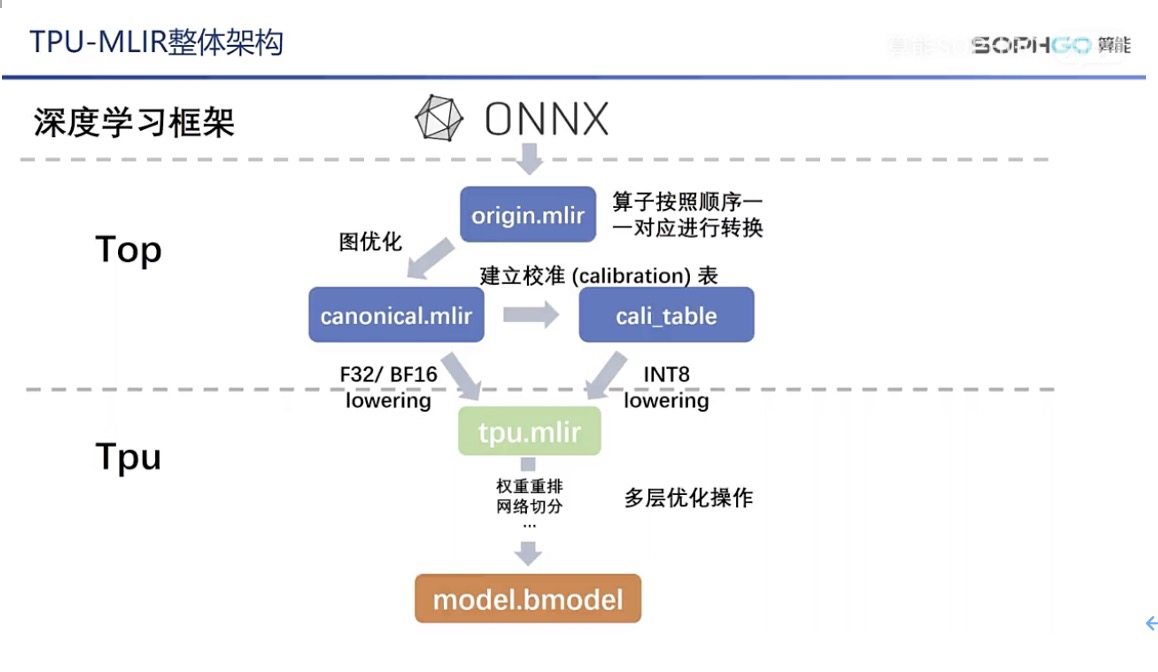
由于国内 MLIR 及 AI 编译器相关的教学资源较少,遇到问题无法有效解决,TPU-MLIR 配套的视频课程将是很好的补充,对于社区用户的疑问,TPU-MLIR 开发者也都会耐心解答。
视频链接:
https://live.csdn.net/v/241401?spm=1001.2014.3001.5501
完善的社区支持,TPU-MLIR 开发者答读者问#
Q:目前 TPU-MLIR 只支持了 1684x 处理器,是否意味着当前的编译器工程只对当前的处理器架构有效?
A:不完全是,开发团队在 TPU 层上做了大量优化操作以进一步提高模型性能,虽然是针对 1684x 实现,但相同的操作也可以应用在其它处理器上,只是在实现方式上有些调整,所以对构建更普适的 AI 编译器有很大的借鉴意义。
Q:TPU-MLIR 的开源工程基于 docker 环境打造,在 docker 中跑出的推理结果能代表处理器上真实的运行结果吗?
A:TPU 处理器主要做的是提高模型的性能,精度主要是由模型本身和转换的过程来决定,理论上来说模型在转换的过程中精度会稍微下降,而工具链实现得越好就越能减少这个过程中精度的损失,我们在 docker 里主要做的是对比原模型和转换后的模型精度,如果精度相差不大,就能保证处理器上的实际运行效果。
Q:编译工具链如何支持 TensorFlow、PyTorch、Caffe 等多种框架编写的模型?
A:现在我们支持新的模型主要的步骤是:
- 根据原模型编写对应的算子转换方法
- 将原模型输入到我们的用户接口尝试进行模型转换
- 解决模型适配过程中出现的问题
- 对比原模型和转换后模型每一层算子的输出结果
- 针对输出结果的不同找出潜在问题并解决
Q:我们知道 TPU 处理器可以实现 AI 训练和推理的加速,这些加速主要是通过哪些过程实现的?
A:TPU 处理器加速本质上是把一个模型拆成一个个算子,然后对每个算子进行转换,最后变成我们处理器可以理解的指令,模型的本质就是数据在一个个算子之间进行运算,然后传递到下一个算子,最后输出结果。
AI 编译器是一项复杂的工程,但是 TPU-MLIR 团队将和众多开发者一起迎难而上,打造出一套可扩展、高性能、对行业有借鉴意义的 AI 编译工具。