近日,TPU-MLIR 开源编译器团队迎来了新鲜血液,经过层层选拔,来自海内外知名高校的 5 位新同学最终入围,他们将与核心开发者一起优化 TPU-MLIR。
TPU-MLIR 的开发也在紧锣密鼓地开展,近期更新了 Caffe 框架支持、算子优化等方面的内容:
- 添加更为复杂的算子,例如 LSTM;
- 部分算子的优化以及支持更多情况,例如 Add 和 Mul 算子的广播(broadcast)操作;
- 之前 TPU-MLIR 主要是支持 int8 量化,现在 FP16/ BFP16 量化也在逐渐完善;
- Caffe 框架的支持进度:目前已经支持 ResNet 和 MobileNet;
TPU-MLIR 的官网也已经正式上线,为了更好地支持全球开发者,中英文版本的开发文档已经同步更新!

新成员谈 TPU-MLIR:充分考虑了硬件特性,精准把握 MLIR 核⼼设计原则#
TPU-MLIR 基于 MLIR 打造,深入理解 MLIR 的底层原理对开发工作有很大的帮助。
MLIR(Multi-Level Intermediate Representation)是一种通用的、可复用的编译器框架,它提供一系列可复用的易扩展的基础组件,用来搭建领域专用编译器。但由于它一开始是为了谷歌的 TensorFlow 而开发的,所以它自带 tensor 类型,这就比它的只有定长 vector 的前辈 LLVM 要更加适应机器学习的相关开发。
在设计上,相较于 LLVM 整体性、强耦合,MLIR 更强调组件性、解耦合。在面对机器学习这样的高层次抽象问题时,MLIR 能够用离散化的方式逐层递降 (lowering)问题的复杂性,原因之一是 MLIR 引入了 Dialect 的概念。
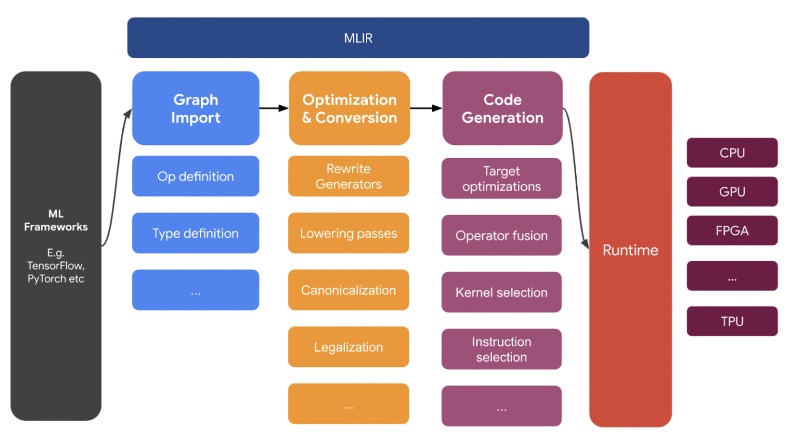
从 IR 的角度看,TPU-MLIR 主要分成两个 Dialect:Top Dialect 和 TPU Dialect。Top Dialect 是⾼层次的与底层⽆关的抽象,在这个层次上的优化也是与硬件⽆关的,⽐如算⼦融合,量化等。TPU Dialect 则包含了底层硬件的细节,其上的优化也充分考虑了硬件的特性,⽐如对内存的管理。
这种设计体现了 MLIR 的核⼼设计原则:分层次的 IR 设计,⽤户程序由⾼级的抽象逐渐转换为低级的抽象,并最终⽣成可以被硬件执⾏的代码,这样设计的好处是每⼀层可以专注于单⼀层的优化和提升,不⽤考虑太多其他层的细节。
对 TPU-MLIR,新成员也提出了一些优化建议,比如目前支持的框架只有 TFLite 和 ONNX,后续可以支持直接转换其他框架模型,减少手写缺失算子的工作量。
社区影响力初现,TPU-MLIR 获 GitHub 开发者认可#
TPU-MLIR 的项目负责人也亲自为大家答疑解惑,关于多处理器支持和模型量化他补充了两点:一,TPU-MLIR 支持将 AI 模型转换到特定的处理器上推理运行,目前只支持 1684x,近期的开发任务不会涉及太多处理器细节,希望大家能收获一些通用的 AI 编译器知识;二,TPU-MLIR 支持浮点模式和 INT8 模式,通常 INT8 模式的性能会是浮点模型的性能的 8 倍以上,所以 INT8 模式会是推理处理器的主流,从浮点到 INT8 的转换称为「量化」。
为什么要进行量化?相比于 FP32,低精度的 INT8 计算对算法的准确率有略微的影响,但带来了巨大的算力提升,适合很多边缘场景。
作为 MLIR 在 ASIC 工具链设计方向的开源实践,TPU-MLIR 也得到了社区开发者的认可,上至顶层架构设计下至实现细节,都有详尽的文档说明,具备非常高的指导价值。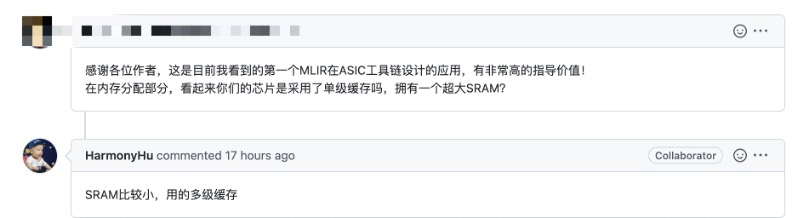
开源短短一个月的时间,GitHub 上的 star 数量已经达到 102 个,这对于一个偏底层开发的编译器项目来说属实不易。
如果你也对 MLIR 及编译器开发感兴趣,欢迎加入到 TPU-MLIR 的开发工作中来,提交项目 PR,体验自己编写的代码在真实场景落地的感觉!