DragGAN Background#
DragGAN originates from the paper titled ‘Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold,’ which was presented at SIGGRAPH 2023. This model takes as input an original image and user interactions (points) and allows for image modifications guided by the user.

The full process of DragGAN includes a forward operation based on the Generator and a backward propagation process. This article primarily focuses on the adaptation of the forward operations within the Generator model.
Model Adaptation#
Loacte, Trace and Export Module#
XingangPan/DragGAN: Official Code for DragGAN (SIGGRAPH 2023) (github.com) is utilized for this adaptation. The entry point of the model can be found at DragGAN/viz/renderer.py:357. Here, you can directly incorporate the gen_shell tool provided by tpu-mlir to trace and generate the workspace folder, onnx/pt models, and the default conversion script.
1 | from utils.gen_shell import generate |
After running the script mentioned in the README.md (python visualizer_drag_gradio.py), and upon successful execution, you will obtain a directory structure similar to the following in the same working directory:
1 | draggan_workspace |
Error Analysis and Resolve During Adaptation#
RuntimeError: Op not support:{‘RandomNormalLike’}#
During the model transformation phase, it was discovered that there is an unsupported operator RandomNormalLike:
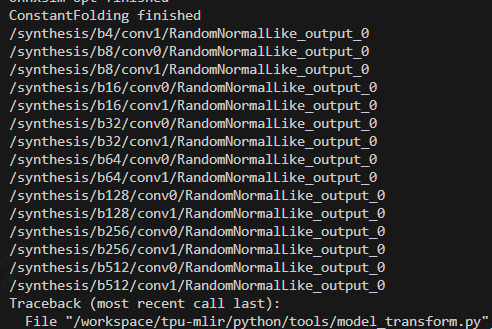
1684x backend not support the operator RandomNormalLike (related to random number generator), so it is necessary to attempt to avoid using these operators in the original model. Upon inspecting the model code, it was found that this operator is used to provide noise for downstream purposes. The source code offers three noise generation methods: random (random noise), const (constant noise), and none (no noise). Therefore, it is possible to avoid the use of this operator by setting noise_mode to const.

Support for Dynamic Convolutional/Deconvolutional Filters#
In the model structure of DragGan, some Conv and DeConv layers have fixed-weight inputs, while the filter is dynamic based on the upstream computation. This situation was not considered before and requires adding support. This involves making code changes in multiple places. Below, we will analyze, locate, and resolve the issues step by step based on specific error messages.
support for model_transform phase#
Within the TPU-MLIR Converter, weights and dynamic inputs are stored in separate variables. Weight information can be obtained using the getWeightOp(name) function, while input data can be retrieved using the getOperand(name) function. If there is uncertainty about whether an operation is a dynamic input or a weight, you can use the getOp(name) function to obtain it.
During the execution of the model_transform.py script for DragGan, An Exception (KeyError) are raised:
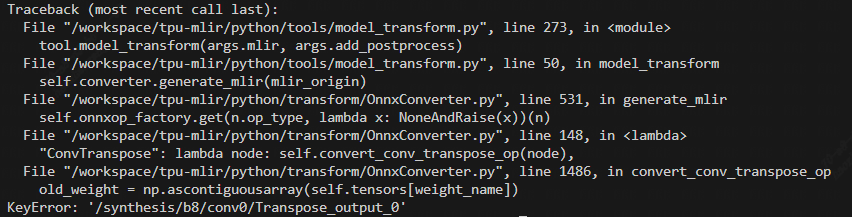
In the current model structure, it has been observed that the input /synthesis/b8/conv0/Transpose_output_0 for this DeConv is obtained as a Weight.
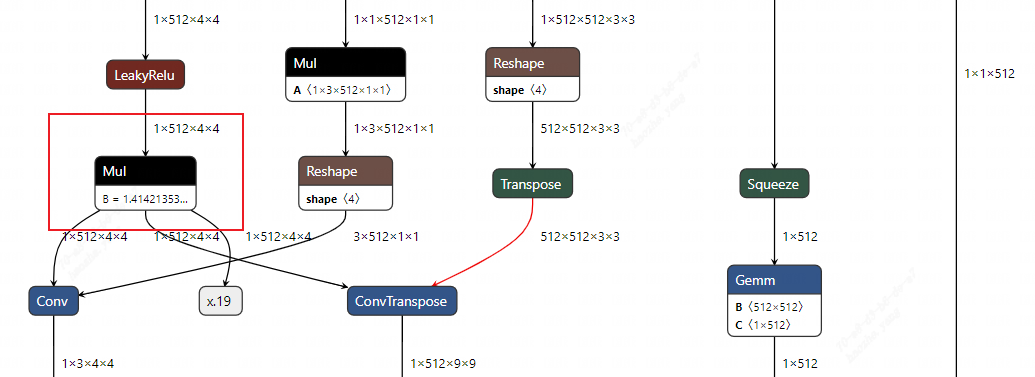
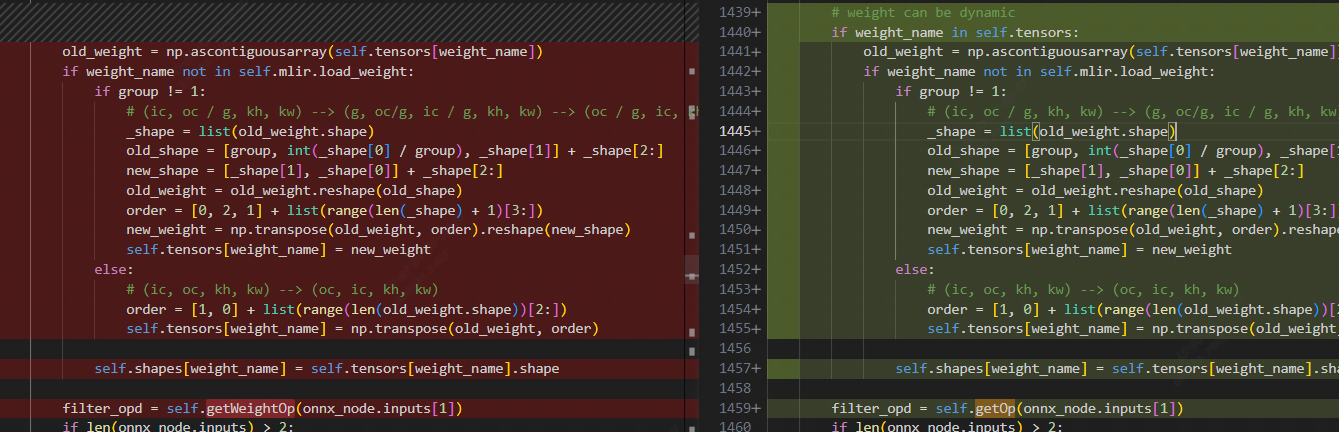
Therefore, the logic for obtaining filter_opd of ConvTranspose should be modified to use getOp.

Similarly, in another KeyError, the filter for DeConv comes from dynamic inputs. So, following the same logic, the filter node retrieval logic for DeConv has also been changed to use getOp.
During the model transformation phase, the model is initially converted to DragGAN_origin.mlir and then goes through processes like --shape-infer and --canonicalize to transform it into an MLIR file described in the Top Dialect, which can be used for inference using model_runner.py. While performing inference on the top-level for correctness validation, the DragGan model encountered an error with zero precision. Upon examining the error message output, it was observed that the precision issue arises after the DeConv layer, and this problem only occurs when the filter for DeConv is a dynamic input.
This error can be successfully reproduced by constructing a DeConv Layer with a dynamic input filter:
1 | class DeConvCase(nn.Module): |
此时通过断点调试,发现错误原因有两个:
- 正确性验证阶段推理时,在
init()时设置权重,此时 weight 还没有设置 - 动态输入时没有做对应的权重重排(WeightReorder)
After debugging, two reasons for the error were identified:
- During correctness validation phase (run mlir file with
model_runner.py), the weights were set in theinit()function, but at this point, the weights had not been configured. - Weight reordering was not performed for dynamic inputs.
The process of adapting models with TPU-MLIR involves multiple steps of transformation and optimization. To ensure the correctness of the transformed model, TPU-MLIR performs three correctness verifications, specifically targeting the Top Dialect, Tpu Dialect, and bmodel. The core code for correctness verification at the Top and Tpu layers resides in ModuleInterpreter.[h/cpp]. This process starts from the input, allocates space for each Op, initializes them, performs inference after initialization, and finally deallocates each Op at the end. One of the accuracy errors in DeConv arises from the separation of initialization and inference during the Inference phase.
During the initialization (init) phase, DeConv constructs an instance of Dnnl and directly make a copy of the Weight into the Dnnl instance. However, since this filter is a dynamic input and its value hasn’t been passed during initialization, the values passed into the filter are essentially all zeros. This leads to errors during the inference phase. After identifying the issue, it can be relatively easily fixed by moving the setup of the Dnnl instance from the initialization phase to the inference phase. The same logic applies to Conv, and the modification process is the same.
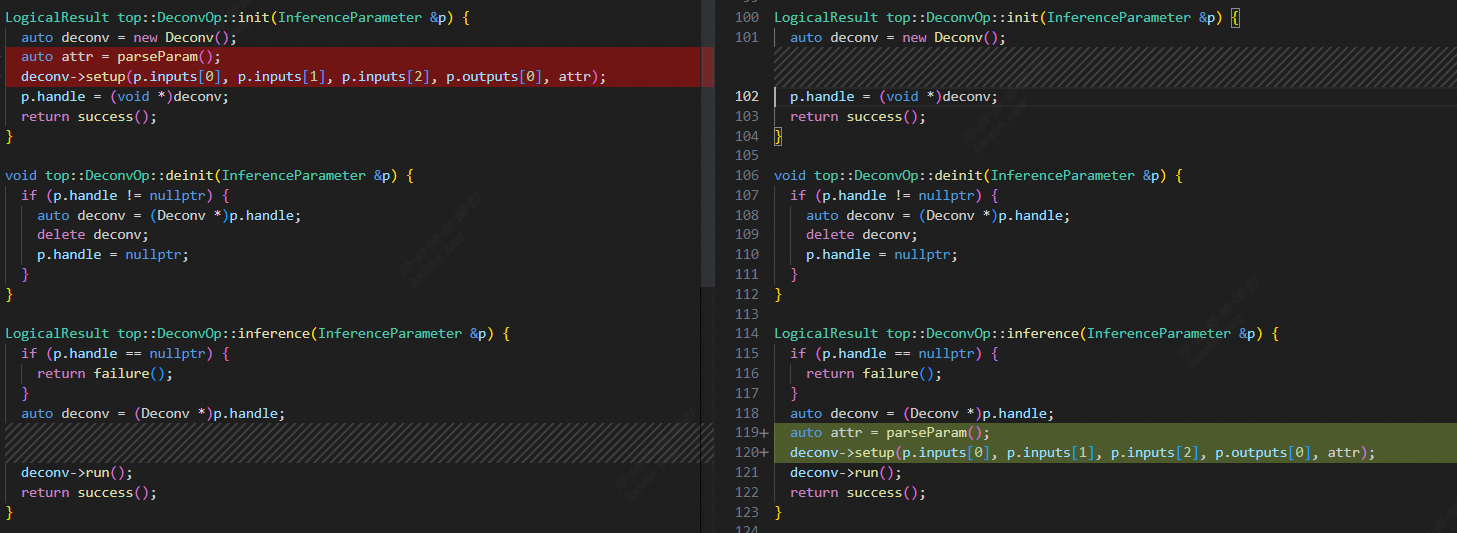
For ONNX models, the DeConv layer’s filter weight storage format is “input channel first,” which means the shape is [ic, oc, kw, kh]. However, most backend computation processes require the “output channel first” format [oc, ic, kw, kh]. It’s worth noting that in the OnnxConverter, there is a transpose operation applied to the DeConv weights to accommodate this format difference.
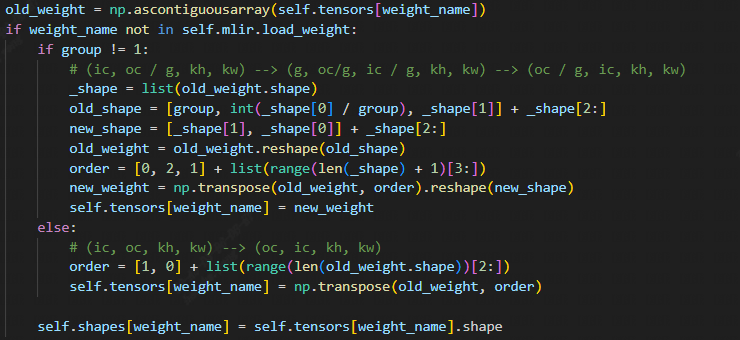
However, it is naturally impossible to implement this operation with dynamic weights. Therefore, an additional graph optimization is required. When the filter of DeConv is dynamic, a [oc, ic] permutation operation is added before it. When adding the Permute operation, careful consideration should be given to the prerequisites for adding this Permute to DeConv. Ensure that the addition of this Permute is specific to the dynamic weights of DeConv and that it is not added redundantly. Therefore, consider adding a boolean parameter called dynweight_reordered to the Operation structure of DeConv. When the filter is not top.WeightOp (using dynamic weights) and dynweight_reordered is false (indicating that a Permute for dynamic weight has not been added), add this Permute and set the dynweight_reordered parameter to true.
After adding the dynweight_reordered parameter to DeConv in the TopOps.td file, the graph optimization logic for DeConv with dynamic weights is as follows:
1 | struct ReorderDynWeight : public OpRewritePattern<DeconvOp> { |
An additional assessment has been made here. When the filter position of DeConv is already permuted, and its order matches the one to be added (1, 0, 2, 3), the two Permutes can be directly merged, allowing for the immediate removal of the Permuted operation and its return. In other cases, an extra Permute operation is inserted. Similarly, dynamic weight rearrangement must be supported for the Conv layer, necessitating the addition of an equivalent graph optimization.
In addition, the shape-infer for the Top layer should precede graph optimization. Therefore, when performing shape-infer, the dynamic weight’s shape should still be in the input channel-first format. Consequently, the determination of dim[1] for the output_shape of DeConv should be based on filter_shape[1]. The corresponding modifications can be found in lib/Dialect/Top/Interfaces/Deconv.cpp.

bmodel Runtime Error#
When use model_runner.py to inference bmodel, it meets an assert error: ASSERT /workspace/nntoolchain/TPU1686/bm1684x/cmodel/src/cmodel_common.cpp: gather_data: 207: dst_offset < (1<<18)
Locating this error in a large model can be challenging. Therefore, you can progressively narrow down the scope using mlir_cut.py to obtain the smallest reproducible MLIR.
1 | mlir_cut.py --mlir *tpu.mlir --output_names /synthesis/b64/conv0/Conv_output_0_Conv --input_names /synthesis/b32/conv1/Mul_3_output_0_Mul,/synthesis/b64/conv0/Reshape_3_output_0_Reshape |
The minimal mlir content is like:

Furthermore, a unit test has been constructed that can reproduce this error.
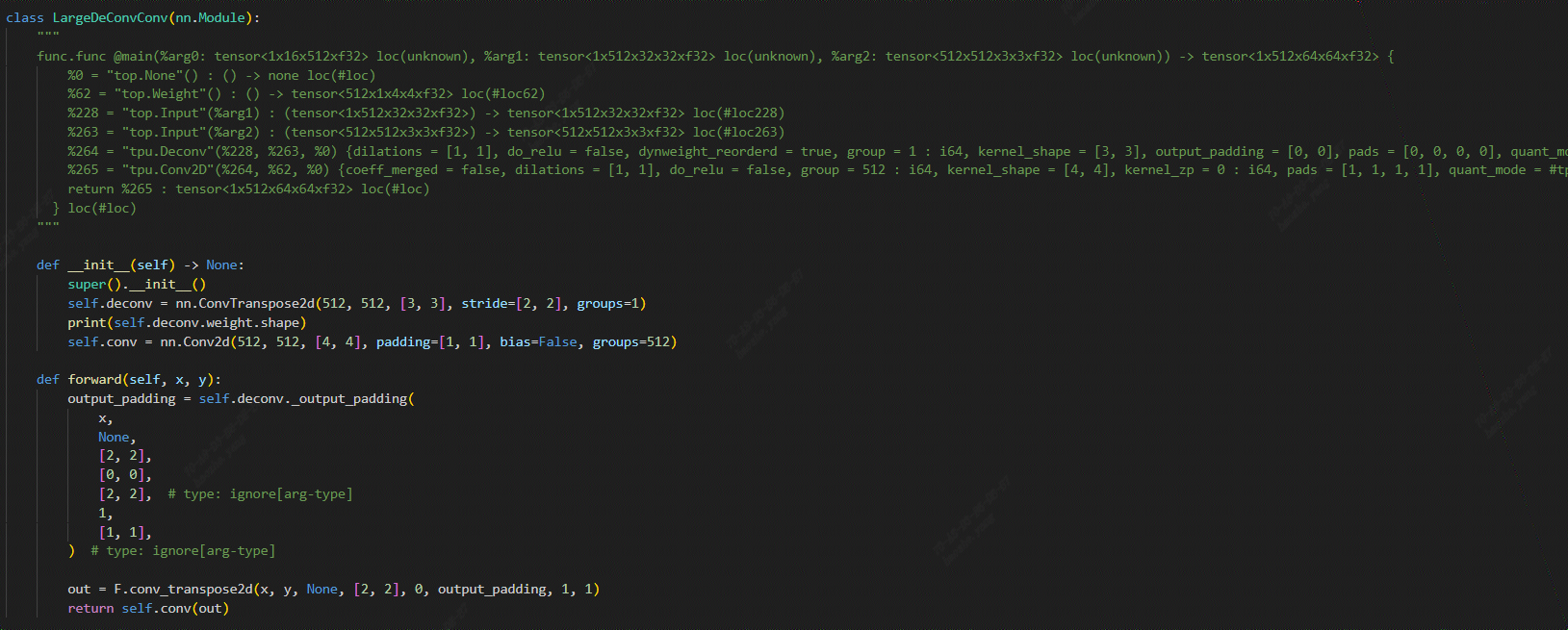
Through controlled experimentation, the following observations have been made:
When
layer-groupis disabled, the model runs without errors. This suggests that the issue primarily lies in the TPU-MLIR portion rather than the backend operator.Changing the DeConv filter from dynamic to static in the provided code allows the model to run without issues, indicating that the problem is still related to dynamic weight handling.
Constructing a basic DeConv operator, whether with static or dynamic weights, runs without problems. In comparison with the one-sided issue mentioned above, it was found that individual DeConv operators do not undergo LayerGroup operations, narrowing down the problem to the LayerGroup section of the TPU-MLIR code.
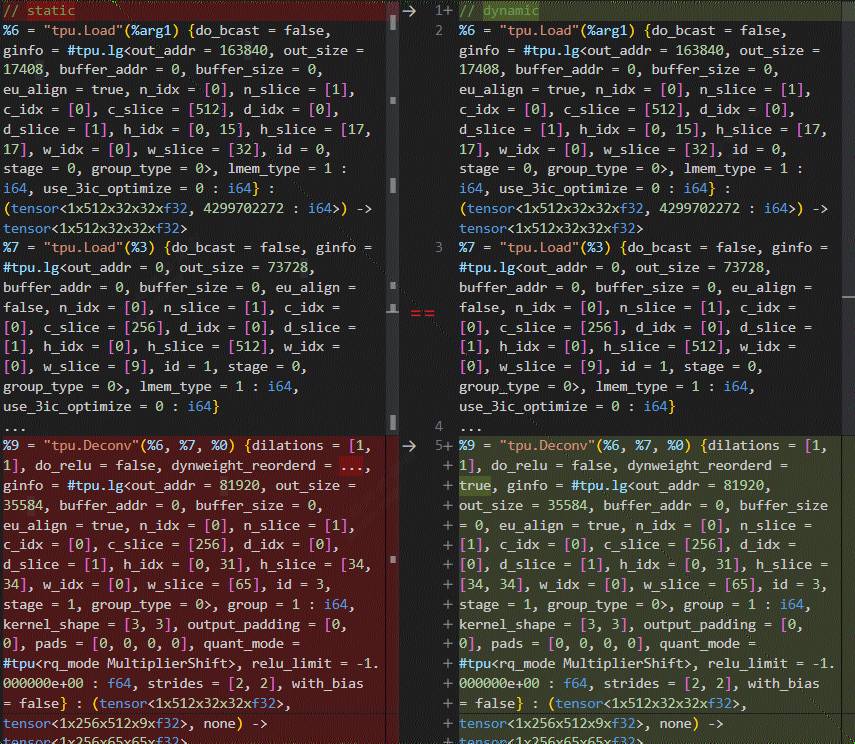
At this point, further comparison between the normal and erroneous final.mlir files reveals inconsistencies in the dynamic weight and weight slice attributes, as shown below:
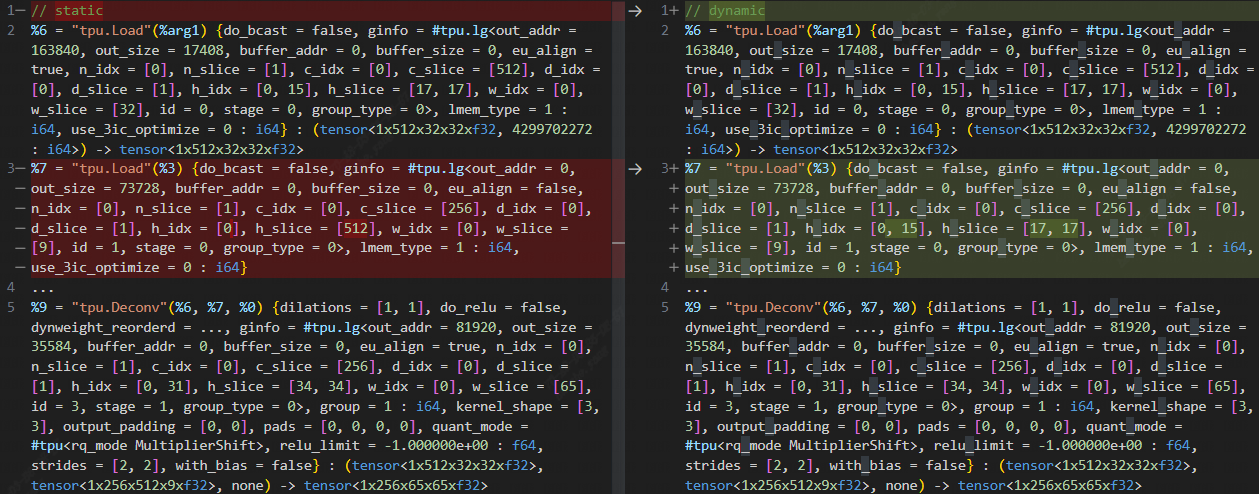
The behavior of top.Weight within the layer-group is indeed unique. In the context of the layer-group, top.Weight is stored entirely in local memory (hold_in_lmem = true). Additionally, weights cannot be sliced, meaning that each slice requires access to the complete filter. This characteristic of top.Weight is what leads to the observed issue in the results.
So, there is a need to handle dynamic weights separately. This involves setting their lifetime (hold_in_mem = true) and configuring their slices to have a length of 1, with elements being values corresponding to their shape dimensions. This process can be implemented within the backward_update_slice method in lib/Dialect/Tpu/Transforms/LayerGroup/LayerGroupUtil.cpp.
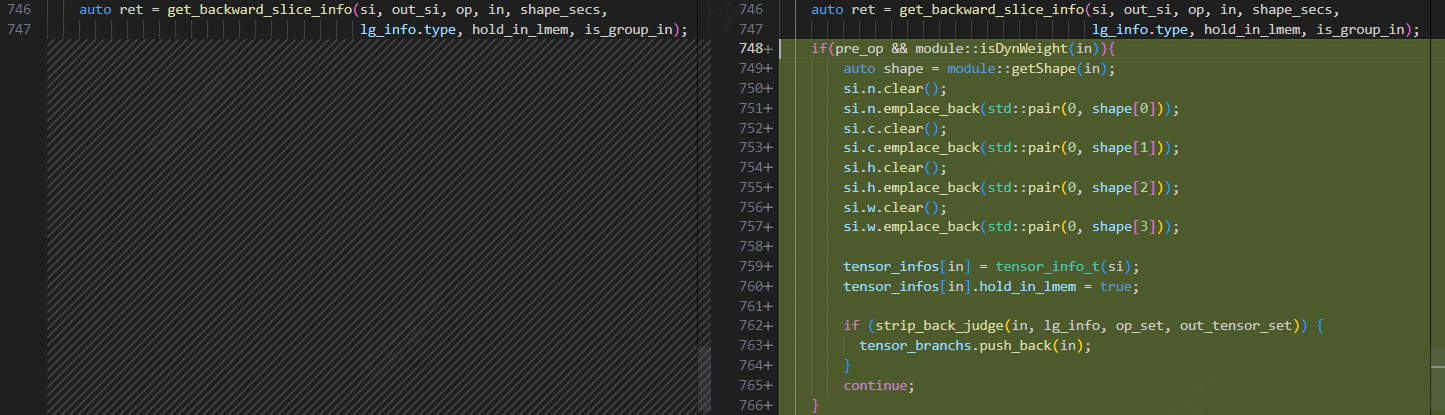
After optimization, upon comparing the final.mlir files of the two instances, it appears that the slice information for dynamic weights is now identical to that of regular weights.
Precision Issue for F16 and int8 data type.#
After resolving the F32 adaptation problems, precision issues still persist in the F16 and int8 TPU layers of MLIR. After conducting inference with correct numerical values for each layer using mlir_debugger (or by directly observing the results in the npz files and comparing them with npz_tool), it was identified that the error lies within the structure involving Active -> Mul where “Active” represents the “ReduceSum” operation in this situation.
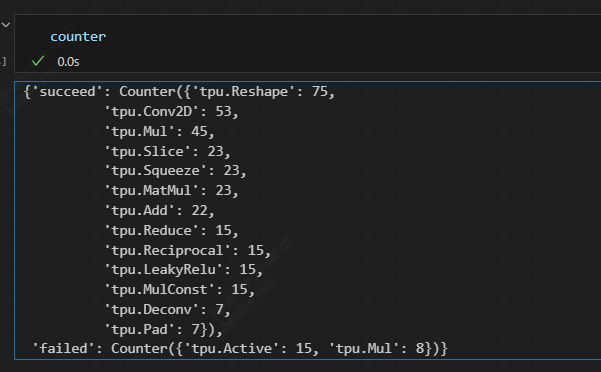
Hence, it can be reasonably concluded that this issue is primarily related to F16 overflow problems. Upon verification with BF16, successful compilation was achieved, providing further confirmation that the problem indeed revolves around overflow in the F16 data type.
When these layers were added to the qtable, it was observed that the comparison still failed, and there were still inf values present within the results. Upon further analysis, it was identified that the issue was caused by two Cast operations within the structure of Active(ReduceSum) -> Sqrt.

The two Cast operations, which were found to be unnecessary, can be optimized out. Subsequently, the optimized MLIR corresponding to this scenario is as follows:

The issue of precision overflow also extends to int8. It has been confirmed that combining the two Cast operations can address the situation for int8 as well.
At this point, the adaptation of the DragGan model is completed.
Conclusion#
In some cases, directly modifying the code structure of the model without affecting the results can make it easier to address certain operator adaptation issues.
When dealing with testing errors in larger models and attempting to locate the issue to specific operators, it’s a good practice to prioritize constructing one-sided tests to replicate the problem.
Controlling variables and establishing control groups is a generally useful approach when seeking solutions in situations where you lack a clear direction for problem-solving.