Overview#
processing flow#
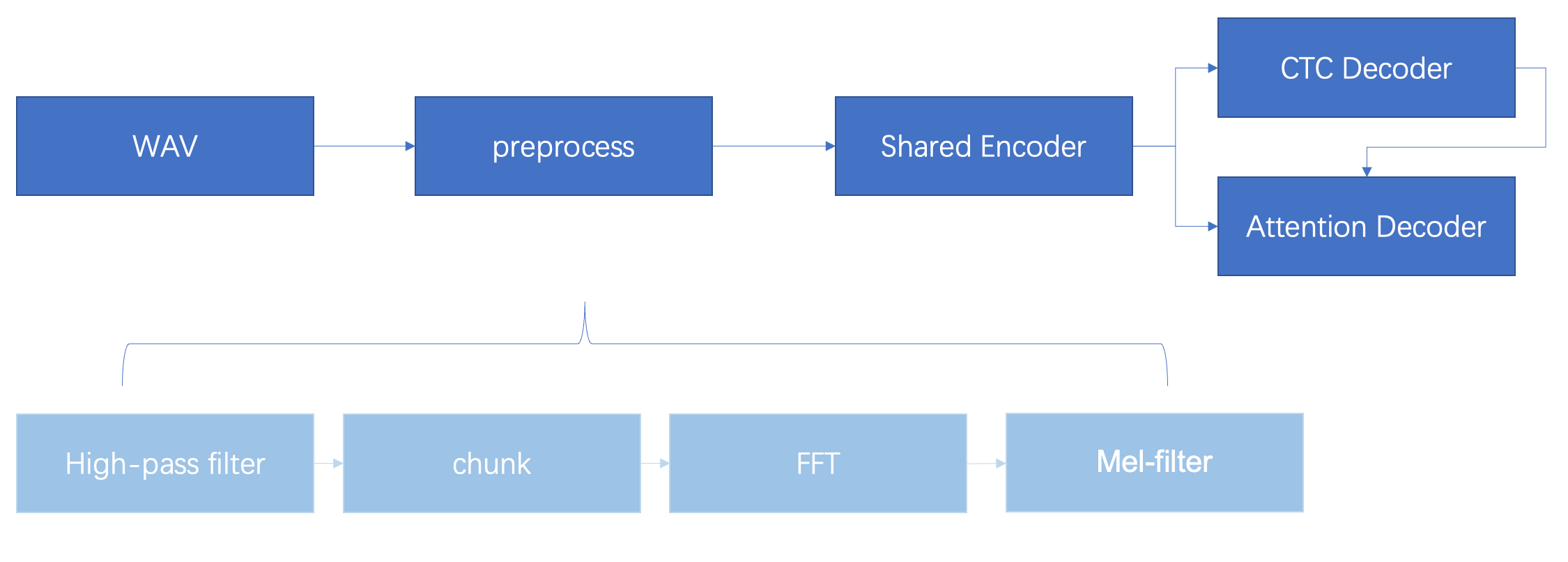
The wav voice undergoes pre-processing before being sent to the encoder. The output of the encoder is then passed to both the CTC decoder and the attention decoder. The CTC decoder performs a depth-first search algorithm to find a set of candidate prediction sequences. The structure of the CTC and the encoder’s output are then sent to the attention decoder. The attention decoder scores the prediction sequences, selects the best one, and outputs the result.
model structure#
encoder#
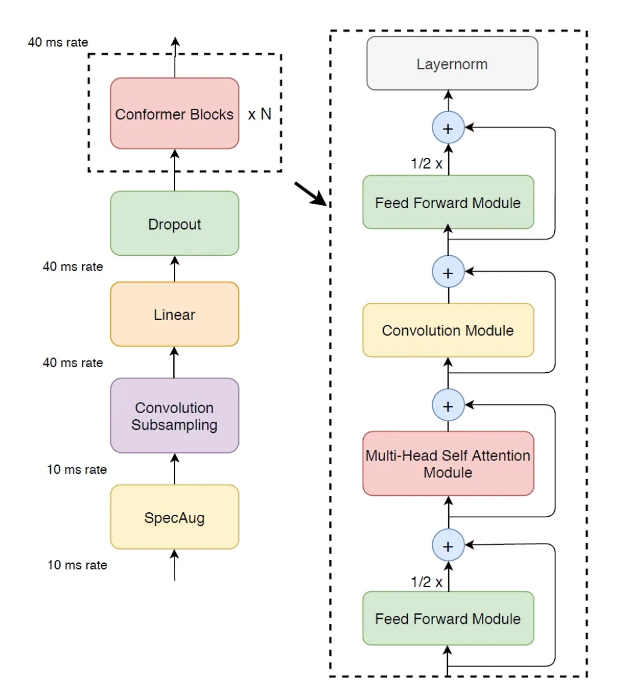
The encoder is composed of a stack of 12 conformer modules.
decoder#
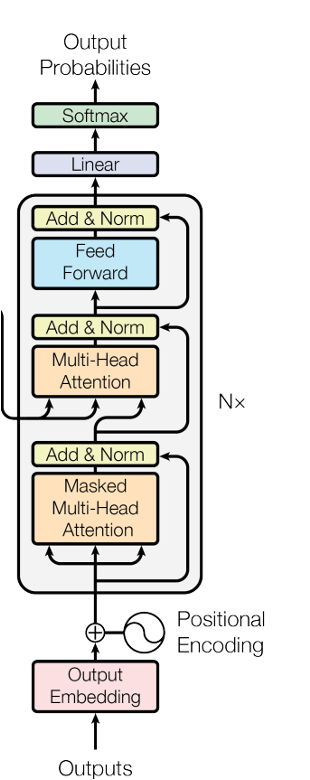
The basic structure of the decoder is a transformer, which first undergoes self-attention for words and then performs cross-attention with mel features. Wenet’s decoder is a bidirectional decoder, with a left-to-right prediction sequence and a right-to-left score. Each decoder consists of a stack of 3 transformers (or 6, depending on the configuration file used during training).
Optimization#
Graph Optimization#
After observing the model graph structure using Netron, the following optimization directions can be considered:
- Deleting redundant operators.
- Operator fusion.
- Changing the operator execution order.
Optimization of Where(MaskedFill)#
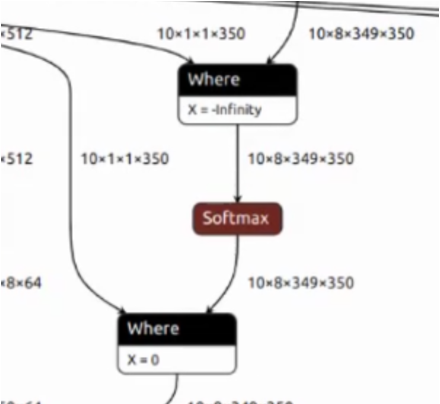
This section of the network performs masking operations by inputting a mask tensor to mask the data. The first “Where” operation sets the unnecessary data to -inf. After applying the softmax function, these data become 0. However, another “Where” operation is added later, setting the same positions to 0 again.
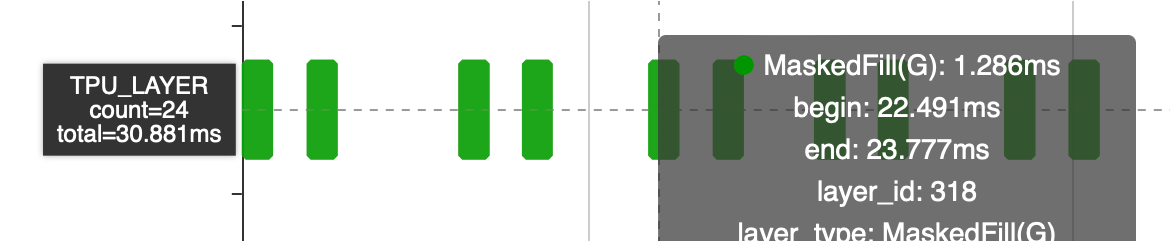
This structure is repeated 12 times in the network, and Where operator takes 30 ms, resulting in a doubling of the computation time. However, by utilizing graph optimization during the compilation phase, this can be eliminated, thereby reducing the computational workload. As a result, the time-consuming operation has been reduced from 30 ms to 15 ms.
Optimization of MatMul#
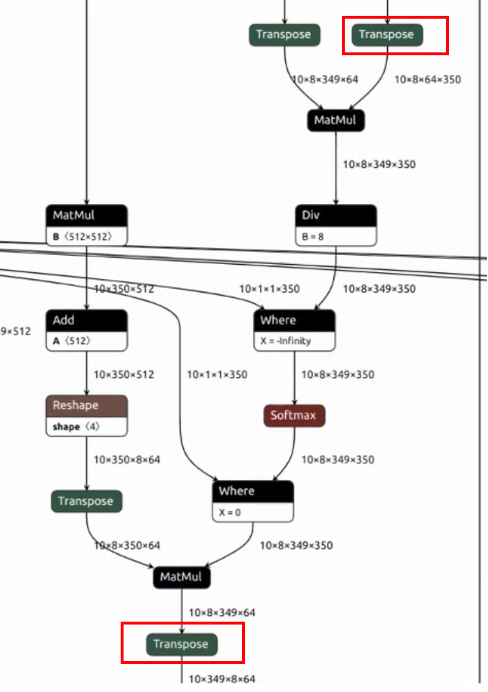
1.This structure appears 6 times in the Decoder and is part of the attention calculation set. However, after transposing, the C dimension is only 8, while our TPU has 64 lanes, so the computing power is not fully utilized.
2.There is a transpose operation to split the layer group and enhance data processing.
optimization:
1.You can optimize the network by using the hdim_is_batch optimization to place the attention head in the h dimension. To ensure the network remains equivalent before and after the transformation, a new transpose operation needs to be generated after the matmul operation.
2.After generating a new transpose, you can implement the optimization pattern for the masked fill operator and the transpose move down of the softmax operator. This allows the transpose operation to be placed at the end of the segment structure, offsetting with the original transpose at the end. This optimization reduces the amount of data handling required.
3.By eliminating the transpose operation, this network can be implemented as a local layer. Additionally, placing 349 in the c dimension allows for the full utilization of computing resources with 64 lanes.
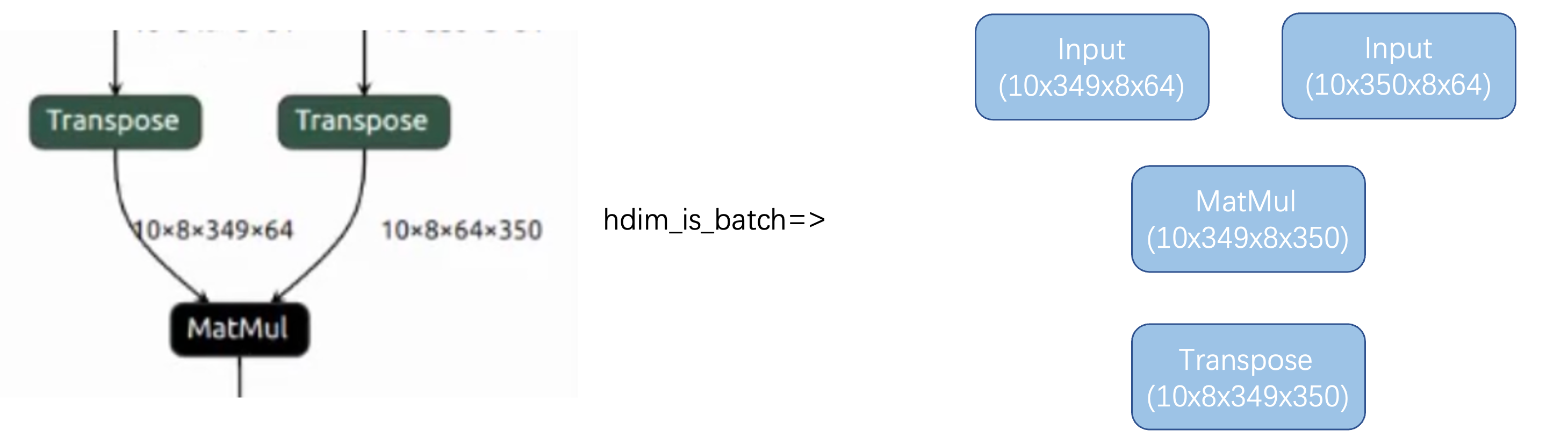
By applying the transpose move down optimization, the remaining operators can be moved down, allowing for the full utilization of the 64 lanes in the local network while keeping C at 349.
Operator level optimization#
Optimization of Where(MaskedFill)#
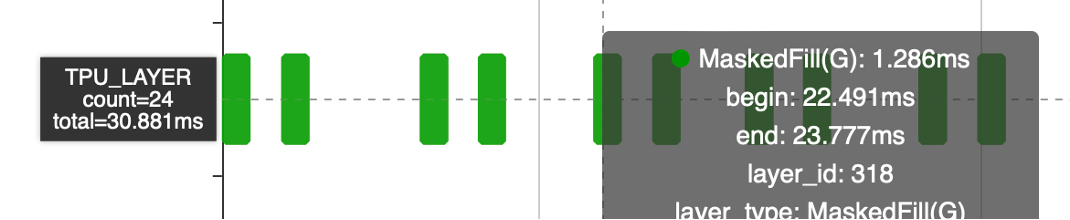
If MaskedFill takes 30ms to go global, even if the number of operators is reduced by half, it will still take 15ms. The Select operator has a local implementation and can perform the MaskedFill function through parameter configuration, but it does not support broadcasting. Therefore, in the compilation stage, Tile is added to complete the broadcast, enabling support for the Local Layer.
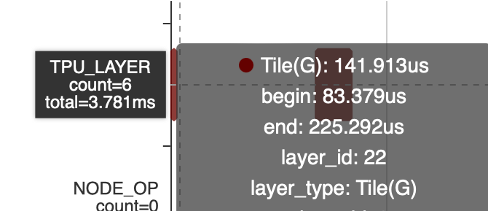
However, with the inclusion of Tile, the Tile operation itself incurs a cost of 3.8ms. Although this cost is acceptable, further optimization can be pursued in the future.
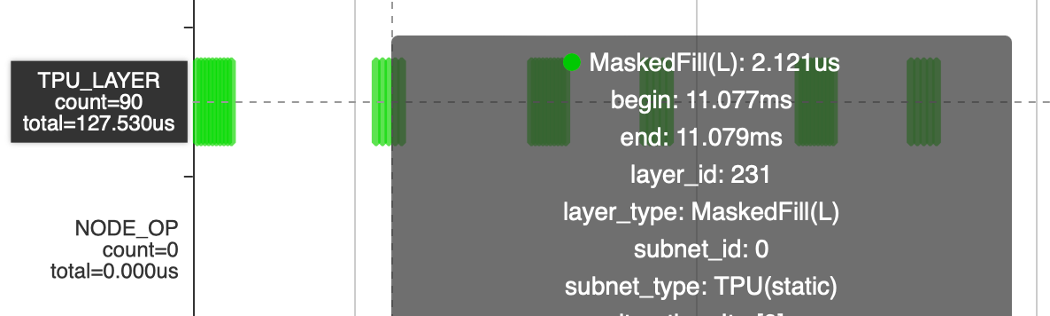
After introducing tiles, the MaskedFill operator was reduced from 30ms to 15ms, and further reduced to 3.8ms (Tile) + 127us (MaskedFill). In the future, it is recommended to consider using bdc to complete the tile operation and achieve further optimization.
Optimization of CPU Layer#
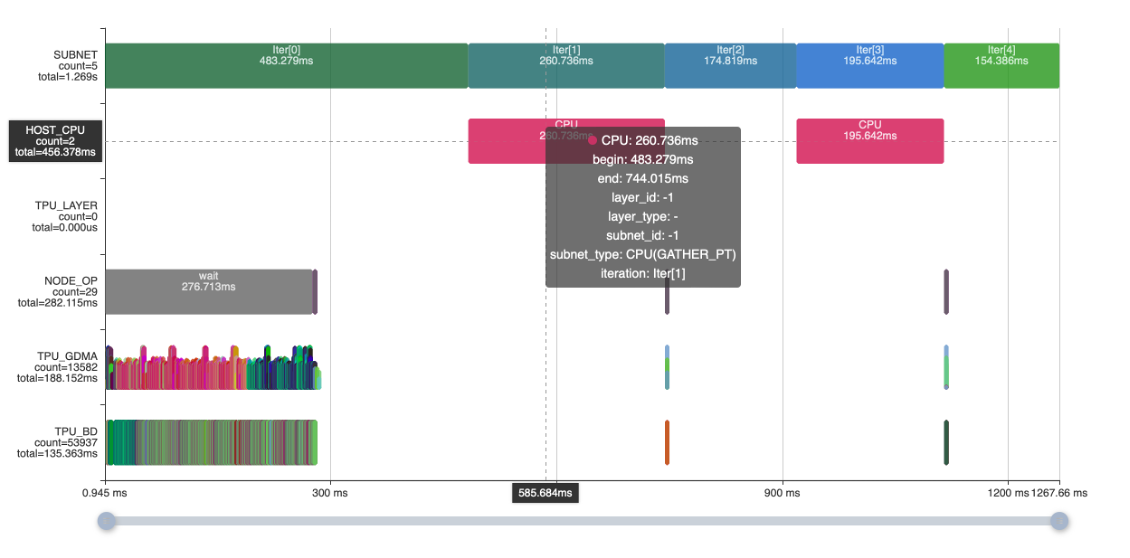
The Gather PT operation on two CPUs takes 456ms, while the Gather operation using DMA can be utilized to implement the operator on the TPU.
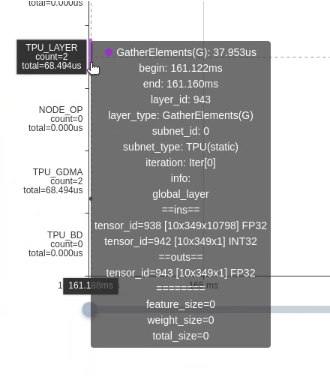
Gather PT operator reduced from 456ms to 68us
Results#
| WeNet Decoder | time |
|---|---|
| original model | 611ms |
| CPU Layer Replacement | 156ms |
| MaskedFill halved | 141ms |
| MatMul hdim_is_batch optimization + Permute Move optimization + MaskedFill supports Local | 71ms |