近几年,以深度学习为代表的 AI 技术发展迅猛,深度神经网络广泛应用于各行各业。
一、算能 TPU 编译器开源,架起算力硬件和 AI 框架的桥梁#
开发者使用 TensorFlow、PyTorch、PaddlePaddle 等深度学习框架可以快速训练出自己的 AI 模型,但这些模型想要部署到 TPU、GPU 等终端算力设备时,需要将模型中的计算图/算子等输出为低级的机器语言更快地执行,这时 AI 编译器就有用武之地了。
作为 框架和硬件之间的桥梁 ,AI 编译器可以实现一次代码开发,各种算力处理器复用的目标。最近,算能也将自己研发的 TPU 编译工具 TPU-MLIR 开源了。
TPU-MLIR 是一个专注于 AI 处理器的 TPU 编译器开源工程,提供了一套完整的工具链,可以将不同框架下预训练过的深度学习模型,转化为可以在 TPU 上运行的二进制文件 bmodel,从而实现更高效的推理。
MLIR(Multi-Level Intermediate Representation,多级的中间表示)是一种用来构建可重用和可扩展编译基础设施的新方法,由 LLVM 原作者 Chris Lattner 在 Google 工作时期开发,MLIR 目的是做一个通用、可复用的编译器框架, 解决软件碎片化,改进异构硬件的编译,显著减少构建特定领域编译器的成本 。
TPU-MLIR 站在 MLIR 巨人的肩膀上打造,现在整个工程的所有代码都已开源,向所有用户免费开放。
二、精度与效率并存,TPU-MLIR 实现主流框架全支持#
TPU-MLIR 相对其他编译工具,有以下几个优势:
简单:通过阅读开发手册与工程中已包含的样例,用户可以了解模型转化流程与原理,快速上手。并且,TPU-MLIR 基于当前主流的编译器工具库 MLIR 进行设计,用户也可以通过它来学习 MLIR 的应用。
便捷:该工程目前已经提供了一套完备的工具链,用户可以直接通过现有接口快速地完成模型的转化工作,不用自己适配不同的网络。
通用:目前 TPU-MLIR 已经支持 TFLite 以及 onnx 格式,这两种格式的模型可以直接转化为 TPU 可用的 bmodel。如果不是这两种格式呢?实际上 onnx 提供了一套转换工具,可以将现在市面上主流的深度学习框架编写的模型转为 onnx 格式,然后就能继续转为 bmodel 了。
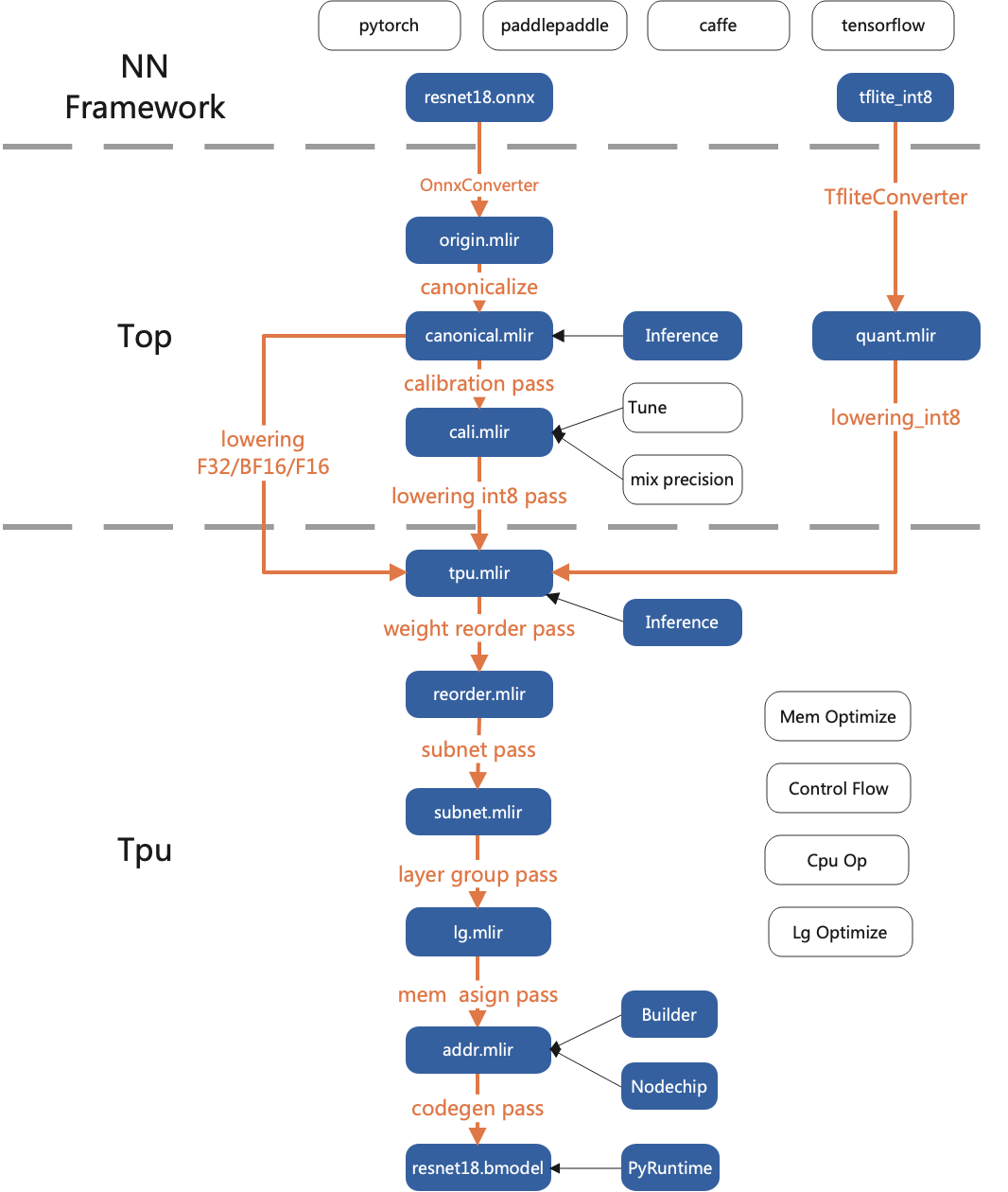
TPU- MLIR 的工作流
精度与效率并存:模型转换的过程中有时会产生精度损失,TPU-MLIR 支持 INT8 对称和非对称量化,在大幅提高性能的同时又结合原始开发企业的 Calibration 与 Tune 等技术保证了模型的高精度。不仅如此,TPU- MLIR 中还运用了大量图优化和算子切分优化技术,以保证模型的高效运行。
目前 TPU-MLIR 工程已被应用在算能研发的最新一代人工智能处理器 BM1684x 上,搭配上处理器本身的高性能 ARM 内核以及相应的 SDK,能够实现深度学习算法的快速部署。
三、实现极致性价比,打造下一代 AI 编译器#
神经网络模型想要支持 GPU 计算,就要把神经网络模型里面的算子开发一个 GPU 版本,如果要适配 TPU,又要把每个算子开发一个 TPU 的版本,还有的场景需要适配同种算力处理器不同型号的产品,每次都要手工编译的话,会非常耗时耗力。
AI 编译器正是为了解决上面的问题而生,TPU-MLIR 的一系列自动优化工具可以节省大量的人工优化时间,让 CPU 上开发的模型可以平滑、零成本地移植到 TPU 上,实现极致性价比。
随着 transformer 等神经网络结构的出现,新的算子不断增加,不仅需要实现出来,还需要结合后端硬件的特点进行优化和测试,尽量将硬件的性能压榨到极致,这也导致算子的复杂度越来越高,调优难度变大,而且并不是所有的算子都能通过一个工具有效生成,整个 AI 编译器领域仍然处于一个不断完善的状态。
TPU- MLIR 也需要持续的研发投入,更多的 AI 处理器支持,代码生成性能优化,运行时调度优化等环节还有很大提升空间,用户在使用本工程的同时也可以参与到该项目的完善与改进工作中,跟算能一起打造一款站在时代前沿的 AI 编译器!