In recent years, AI technology represented by deep learning has developed rapidly, and deep neural networks are widely used in all walks of life.
SOPHGO open-source TPU compiler builds a bridge between computing hardware and AI framework#
Developers can quickly train their AI models using TensorFlow, PyTorch, PaddlePaddle and other deep learning frameworks. However, if users want to deploy these models to terminal computing devices such as TPU and GPU, they need to output the computing graphs/operators in the model as low-level machine language for faster operation. At this time, AI compilers have a place to play.
As a bridge between framework and hardware, AI compilers can realize the goal of code development and reuse of various computing chips. Recently, SOPHGO has also opened its own TPU compilation tool TPU-MLIR.
TPU-MLIR is a TPU compiler open-source project focusing on AI chips. It provides a complete toolchain, which can transform the pre-trained deep learning model under different frameworks into a binary file bmodel that can run on TPU to reason more efficiently.
MLIR (Multi-Level Intermediate Representation) is a new method for building reusable and extensible compilation infrastructure. It was developed by Chris Lattner, the original author of LLVM, during his work at Google. MLIR is proposed to make a general and reusable compiler framework, solve software fragmentation and improve the compilation of heterogeneous hardware to significantly reduce the cost of building domain-specific compilers.
TPU-MLIR was built on the shoulders of MLIR. Now all the codes of the whole project have been open-source and are free to all users.
Accuracy and efficiency coexist, and TPU-MLIR realizes full support of mainstream frameworks#
Compared with other compilation tools, TPU-MLIR has the following advantages:
Simple: by reading the development manual and the examples included in the project, users can understand the process and principle of model transformation and get started quickly. Moreover, TPU-MLIR is designed based on the current mainstream compiler tool library MLIR, and users can also learn the application of MLIR through it.
Convenience: the project has provided a complete set of toolchains. Users can quickly complete the transformation of models through existing interfaces without adapting to different networks.
General: TPU-MLIR now supports TFLite and onnx formats. The models of these two formats can be directly converted into bmodel available for TPU. What if it is not in these two formats? In fact, onnx provides a set of conversion tools, which can convert the model written by the mainstream deep learning framework in the market to onnx format, and then continue to convert to bmodel.
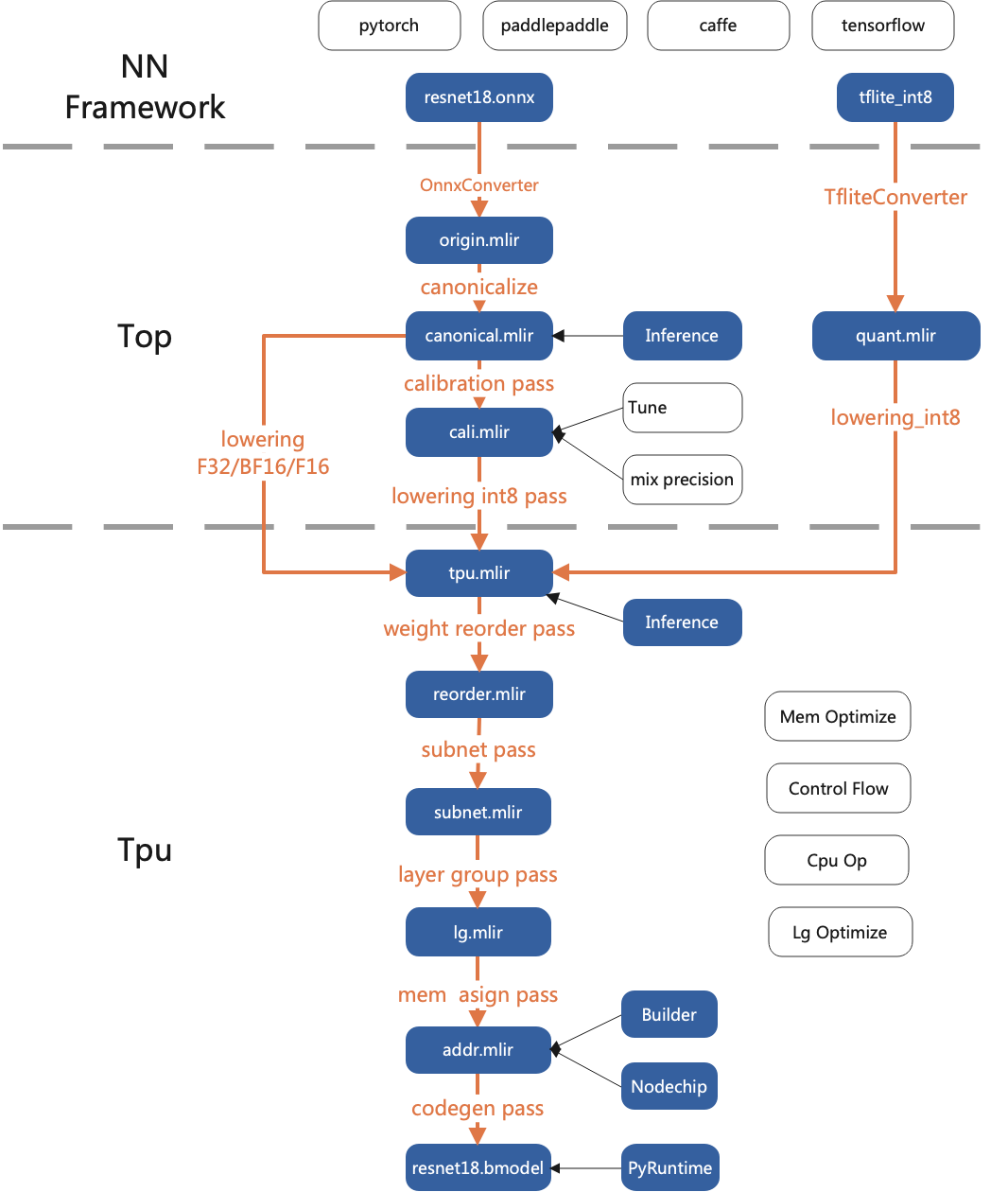
Workflow of TPU-MLIR
Accuracy and efficiency coexist: accuracy loss sometimes occurs in the process of model conversion. TPU-MLIR supports INT8 symmetric and asymmetric quantization, which greatly improves the performance and ensures the high accuracy of the model in combination with the Calibration and Tune technologies of the original development enterprise. In addition, TPU-MLIR also uses a large number of graph optimization and operator segmentation and optimization techniques to ensure the efficient operation of the model.
Currently, the TPU-MLIR project has been applied to the latest generation of artificial intelligence processor BM1684x developed by SOPHGO, which can realize the rapid deployment of deep learning algorithms with the processor’s high-performance ARM core and corresponding SDK.
Achieve extreme cost effective and create the AI compiler of the next generation#
If the neural network model wants to support GPU calculation, it needs to develop a GPU version of the operators in the neural network model. If it needs to adapt to TPU, it needs to develop a TPU version for each operator. In other scenarios, it needs to adapt to products of different models of the same kind of computing processor. If manual compilation is required each time, it will be time-consuming and laborious.
AI compiler is designed to solve the above problems. A series of automatic optimization tools of TPU-MLIR can save a lot of manual optimization time so that the models developed on CPU can be smoothly and cost-effectively migrated to TPU to achieve ultimate cost performance.
With the appearance of neural network structures such as transformer, the number of new operators are constantly increasing. These operators need to be realized, optimized and tested according to the characteristics of the back-end hardware to perfect the performance of hardware. This also leads to the higher complexity of operators and greater difficulty in tuning, and not all operators can be effectively generated by one tool. The whole AI compiler field is still in a state of continuous improvement.
TPU-MLIR also needs continuous R&D investment, AI processor support, code generation performance optimization, runtime scheduling optimization and other links that have a lot of room for improvement. Users can also participate in the improvement of the project and cooperate with SOPHGO to create an AI compiler that stands at the forefront of the times!