众所周知,一个完整的模型实际上是由一系列算子组成的,所以如果我们想让编译器更通用,那么支持尽可能多的算子就是一个绕不开的工作。
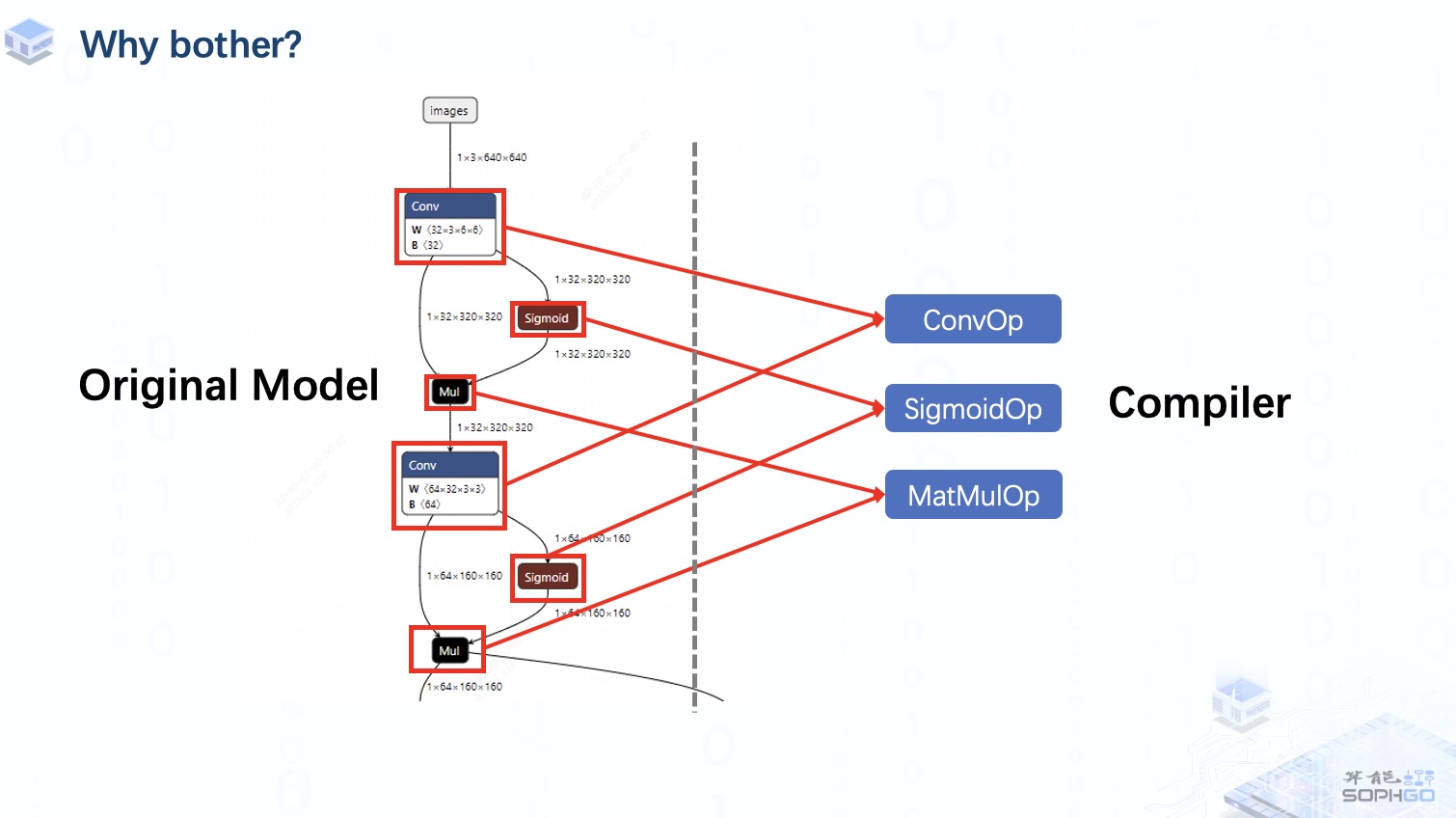
这样无论算子是来自onnx、Caffe、PyTorch中的哪个框架,我们都可以在TPU-MLIR中找到对应的算子来表达。
首先,要添加一个新的算子,我们就需要像前端转换那一集里提到的先进行算子定义。

在 MLIR 中,您可以直接使用 TableGen 工具来完成定义工作,而不是自己实现所有包含每个算子的输入、输出和属性的 cpp 模板。
在 TPU-MLIR 中,不同 dialect 的算子定义在不同的 td 文件中,这些算子将在编译器 build 时注册在相应的 Dialect 下。
但是定义部分只是生成了模板,也就是说,我们的编译器还不知道这个算子会对输入张量做什么处理,所以我们需要通过实现相应目录下的 inference 方法来完成这部分工作。

在 Top dialect 中,除了 inference 接口,我们还需要为每个算子实现是 FLOPs 和 Shape 接口。 前者用于计算浮点运算量,后者用于在输出 shape 未知的情况下推理出输出 shape。
在 MLIR 中,我们有 RankedTensorType 和 UnRankedTensorType。
这些接口的声明是在 td 文件中被要求的,所以所有从 Top_Op 类派生的算子都需要声明这些接口。
同样,我们还必须为每个 Tpu 算子实现 inference 接口。 由于我们可以直接从 Top 算子获取 FLOPs 和 Shape 信息,所以这里不需要再实现这些接口。
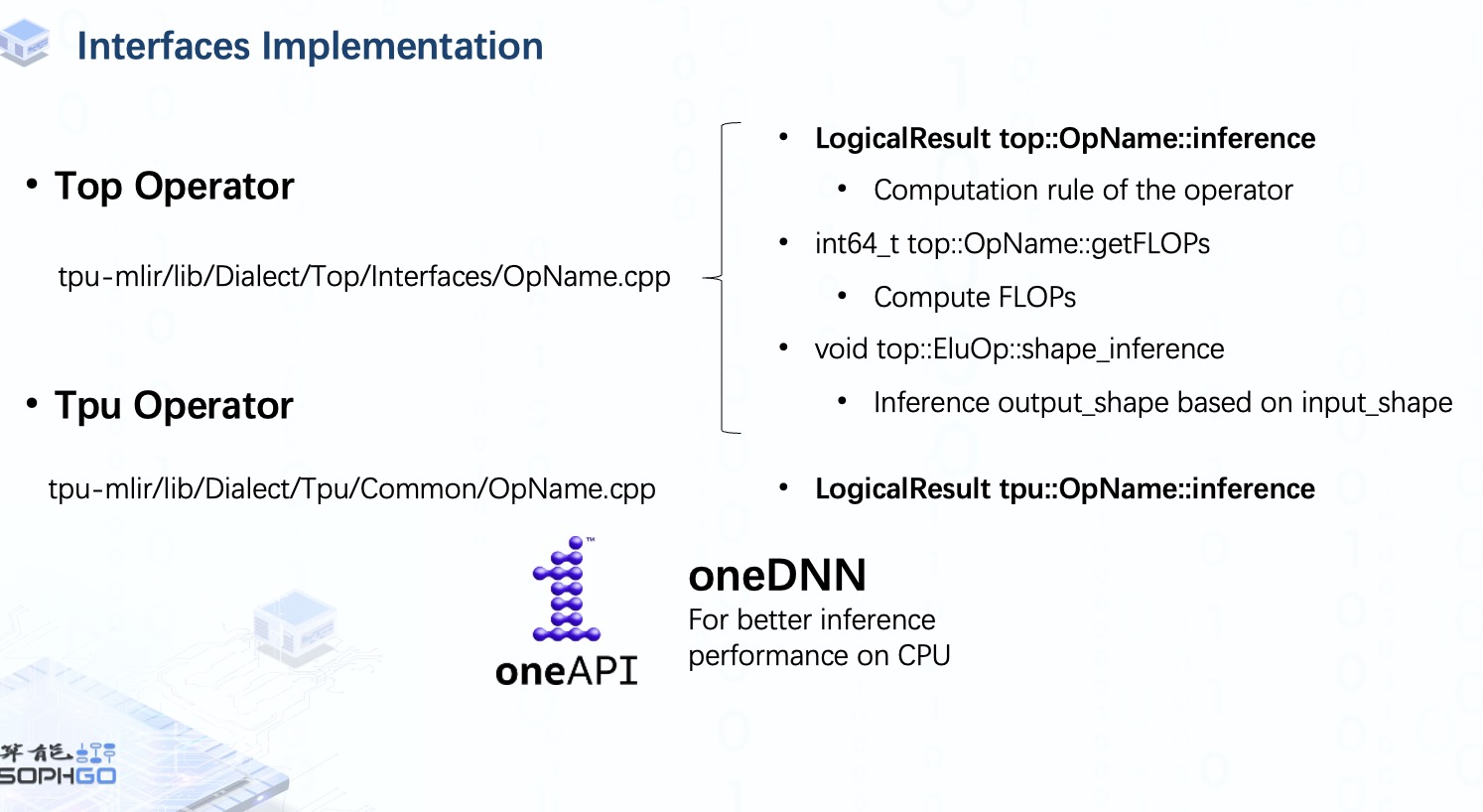
由于 Top 和 Tpu 算子是在 CPU 上做推理工作,所以有时我们会把推理工作交给 oneDNN,一个跨平台的神经网络库,主要用于提高 CPU 上的推理性能。 不过这部分我就不再细说,如果大家有兴趣的话,我们可以再做一个视频来介绍一下。
所以如果大家想了解 oneDNN 的话,记得在视频底下留言让我们知道。
我们知道,TPU 算子最终会被用于不同硬件的代码生成,所以对于这个 Dialect 中的算子,需要为每个硬件实现额外的接口。

其中 LocalGenInterface 用于应用了 LayerGroup 的算子,而 没有应用 LayerGroup 的算子则会使用 GlobalGenInterface。 所以你会看到所有的算子中都有 GlobalGenInterface,但只有其中一部分算子实现了 LocalGen。
在 GlobalGen 中,张量在 Global Memory 里,因此我们需要做的是准备后端 API 所需的所有参数,例如算子的属性以及输入和输出张量的 Global 地址。
对于 LocalGen,张量位于 Local Memory 中,这意味着它已经完成了将 tensor 从 Global 到 Local Mmeory 的搬运,因此我们需要调用 local 的后端 API。 此外,在量化的情况下,有时我们需要计算缓冲区大小以存储中间结果。 这是因为中间结果通常以更高位的数据类型存储。 比如在 int8 量化中,我们需要先将计算结果存储为 int16 或者 int32 数据,然后再重新量化回 int8。
完成定义和接口实现工作后,还有一件需要完成的事情就是 lowering。
在 TopToTpu pass 中,我们需要应用算子转换的 Pattern set,这需要我们为每个硬件中的每个算子实现转换 Pattern。

一共要做 3 步,首先,在头文件中声明 Lowering pattern。 接着,实现该 Pattern, 然后将其添加到 Pattern set 中。
如本例所示,我们在实现 Pattern 部分主要要做的是将当前的 Top op 替换为对应的 Tpu op,并根据指定的量化模式设置该 op 的 Type。
至此,添加新算子的工作就完成了。