19. final.mlir 截断方式
final.mlir 作为 codegen 的输入文件,是模型在经过了所有硬件无关与硬件相关的优化后生成的最终中间表达( IR )。因为包含了硬件相关信息,结构相对于之前的 IR 要复杂的多。
而在进行模型适配时有时会出现 Tpu 层 MLIR 文件与 bmodel 的 cmodel 推理结果不一致的情况,为了快速定位到出问题的位置,除了使用 bmodel_checker.py 工具对每一层输出进行对比外,还可以手动对 final.mlir 文件进行截断,生成一个截断后的模型。
因此,本章主要会对 final.mlir 的结构进行剖析,并讲解如何基于 final.mlir 对模型进行截断以便于后续的问题定位。
建议使用 IDE :VSCode。
建议使用插件:MLIR。
19.1. final.mlir 结构介绍
final.mlir 中的单个算子组成部分如下:

图 19.1 final.mlir 单算子示例
注意:
value 表示算子的输入/输出,为 SSA 形式
out_num:表示输出的数量。如果是单输出算子,则不会显示 :out_num。
对于多输出算子的值,用户将按 %value#in_index 方式引用 ( index 从0开始)
每个输入/输出值都有对应的 Tensor type。
完整的 Tensor type 包含形状、数据类型和全局内存地址( Gmem addr )。
除了单算子外 final.mlir 中还存在着 LayerGroup 后生成的 tpu.Group 算子,其中包含了多个中间算子,这些算子均在 Lmem 上完成计算,由 tpu.Group 统一通过 tpu.Load 和 tpu.Store 控制输入数据加载和输出数据存储,所以中间算子的 Tensor type 并没有 Gmem addr :

图 19.2 tpu.Group 示例
local_type 指代不带有 Gmem addr 的 Tensor type 。
算子尾部的 loc(#loc32) 指代模型某层输出的 location ,即该输出的编号,可根据该编号在 final.mlir 文件尾部找到对应的输出名。
Yield 表示 tpu.Group 的输出集合。
完整的 final.mlir 文件中存在的结构大致如下:

图 19.3 final.mlir 结构示例
双层 module 中 包含了 mainfunc 和 subfunc , mainfunc 和 subfunc 存在调用关系。
mainfunc 中的 arg0 指代 host 端的输入,因此 host_in_type 不带有 Gmem addr 。
多输出的 location 会被添加在 final.mlir 文件的最尾端,并表述出与每个具体输出 location 间的包含关系,例如 #loc950 = loc(fused[#loc2, #loc3]) 。
19.2. final.mlir 截断流程
修改 subfunc 。删减 subfunc 内部结构,并将返回值的 value 与对应 type:

图 19.4 截断流程 Step1
同步 mainfunc 中 subfunc 的调用方式( value 与 type ):
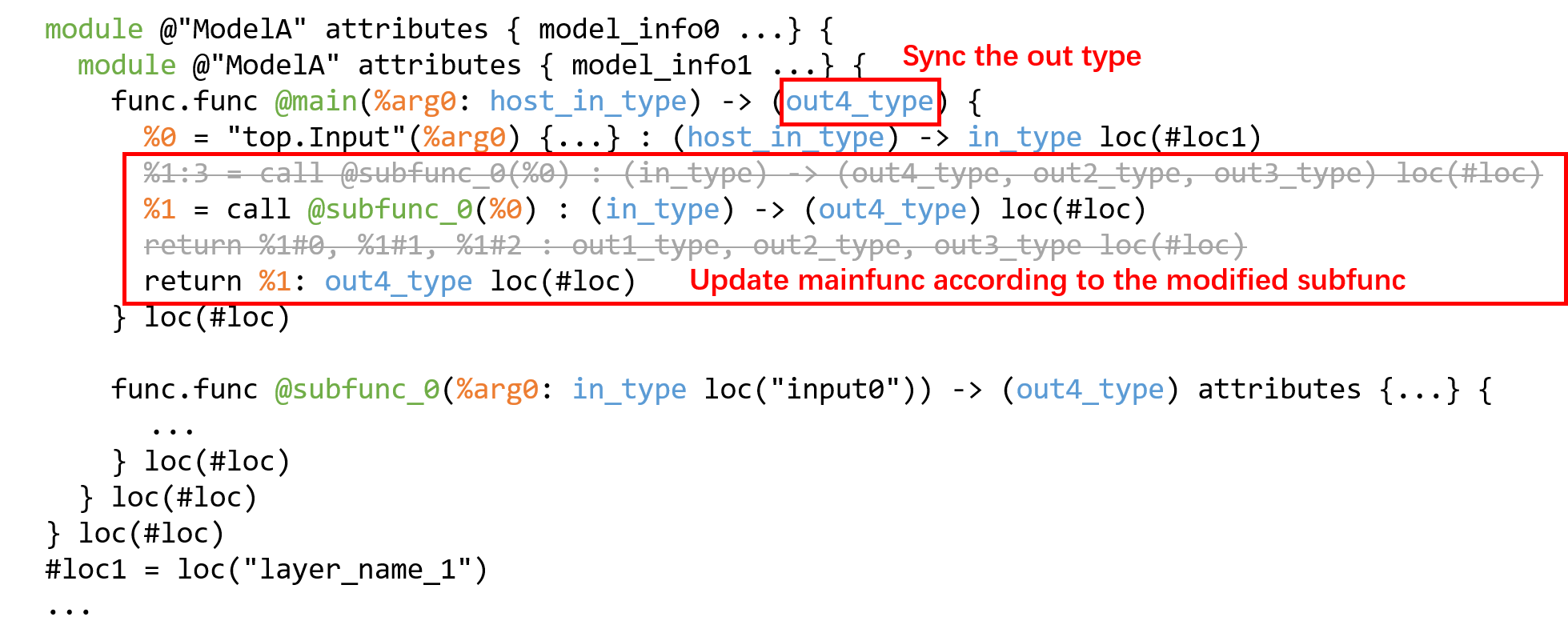
图 19.5 截断流程 Step2
检查 bmodel 是否修改成功。可首先通过执行 codegen 步骤看是否可以正常生成 bmodel (<…> 请替换为实际的文件或参数):
$ tpuc-opt <final.mlir> --codegen="model_file=<bmodel_file> embed_debug_info=<true/false> model_version=latest" -o /dev/null
当需要使用profile进行性能分析时, embed_debug_info 设置为 true 。
使用 model_tool 检查该 bmodel 的输入输出信息是否符合预期:
$ model_tool --info <bmodel_file>
注意:
截断时以算子为单位进行模型结构的删除,每个 tpu.Group 应当被看作是一个算子。
仅修改函数返回值不对冗余的模型结构进行删除可能会造成输出结果错误的情况,该情况是由于每个激活的 Gmem addr 分配会根据激活的生命周期进行复用,一旦生命周期结束,将会被分配给下一个合适的激活,导致该地址上的数据被后续操作覆盖。
需要确保 tpu.Group 的每个输出都有 user ,否则可能会出现 codegen 步骤报错的情况,如果不想输出 tpu.Group 的某个结果又不便将其完整删除,可以为没有user的输出添加一个无意义的 tpu.Reshape 算子,并配上相同的 Gmem addr 和 location , 例如:

图 19.6 reshape 添加示例
对模型进行删减后可以更新 module 模块中的 module.coeff_size 信息以减少裁剪后生成的 bmodel 大小,公式如下:
上述公式中的 weight 指代截断后 final.mlir 中最后一个 top.Weight 。 neuron (即激活)因为会对地址进行复用,因此不建议进行修改。